 lumpics.ru
lumpics.ruСодержание:
Извлечь текст из PDF-файла методом обычного копирования можно далеко не всегда. Часто страницы подобных документов представляют собой отсканированное содержимое их бумажных вариантов. Для преобразования таких файлов в полностью редактируемые текстовые данные используются специальные программы с функцией Optical Character Recognition (OCR).
Такие решения являются весьма сложными в реализации и, следовательно, стоят немалых денег. Если потребность в распознавании текста с PDF у вас возникает регулярно, вполне целесообразно будет приобрести соответствующую программу. Для редких же случаев более логичным будет воспользоваться одним из доступных онлайн-сервисов с подобными функциями.
Как распознать текст с PDF онлайн
Конечно, набор возможностей онлайн-сервисов OCR, в сравнении с полноценными десктопными решениями, более ограничен. Но и работать с такими ресурсами можно либо же совсем бесплатно, либо за символическую плату. Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Способ 1: ABBYY FineReader Online
Компания-разработчик сервиса — одна из лидеров в области оптического распознавания документов. ABBYY FineReader для Windows и Mac является мощным решением для преобразования PDF в текст и дальнейшей работы с ним.
Веб-аналог программы, конечно же, уступает ей по функционалу. Тем не менее сервис умеет распознавать текст со сканов и фотографий на более чем 190 языках. Поддерживается преобразование PDF-файлов в документы Word, Excel и т.п.
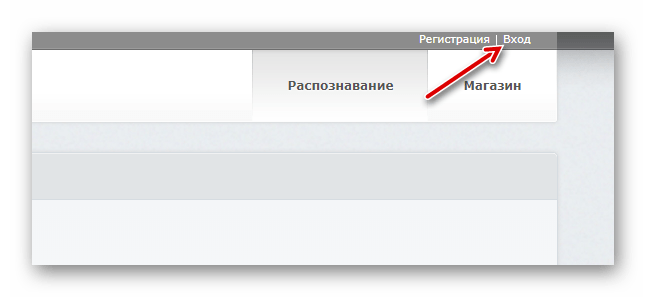
- Прежде чем приступить к работе с инструментом, создайте аккаунт на сайте или войдите при помощи учетной записи Facebook, Google или Microsoft.

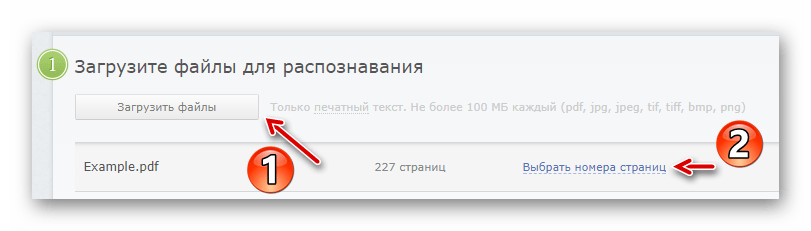
Чтобы перейти к окну авторизации, щелкните по кнопке «Вход» в верхней панели меню. - Осуществив вход, импортируйте нужный PDF-документ в FineReader, воспользовавшись кнопкой «Загрузить файлы».

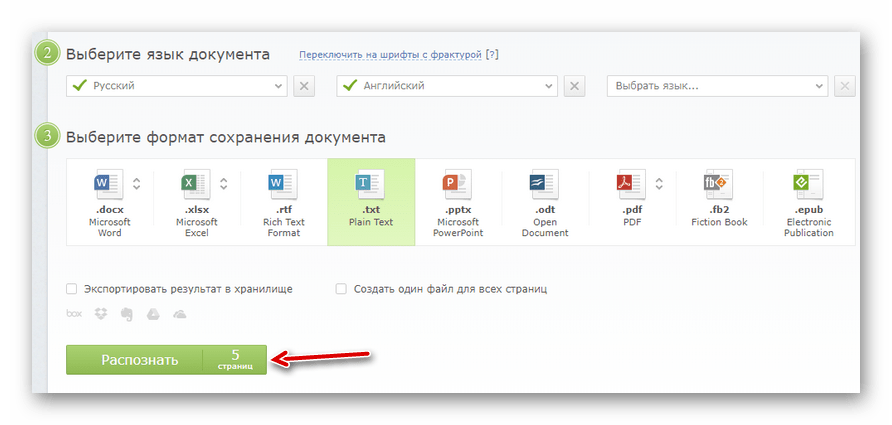
Затем нажмите «Выбрать номера страниц» и укажите желаемый промежуток для распознавания текста. - Далее выберите языки, присутствующие в документе, формат итогового файла и нажмите на кнопку «Распознать».

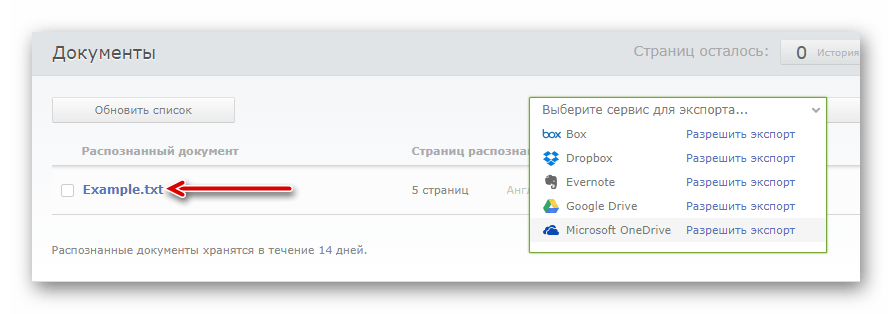
- После обработки, длительность которой полностью зависит от объема документа, вы можете скачать готовый файл с текстовыми данными просто щелкнув по его названию.

Либо же экспортируйте его в один из доступных облачных сервисов.
Сервис отличается, вероятно, наиболее точными алгоритмами распознавания текста на изображениях и PDF-файлах. Но, к сожалению, его бесплатное использование ограничено пятью обрабатываемыми страницами в месяц. Чтобы работать с более объемными документами, придется купить годовую подписку.
Тем не менее, если функция OCR нужна совсем уж редко, ABBYY FineReader Online — отличный вариант для извлечения текста из небольших PDF-файлов.
Способ 2: Free Online OCR
Простой и удобный сервис для оцифровки текста. Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
При регистрации пользователь получает возможность обрабатывать многостраничные документы, однако бесплатное количество этих самых страниц ограничено 50 единицами.
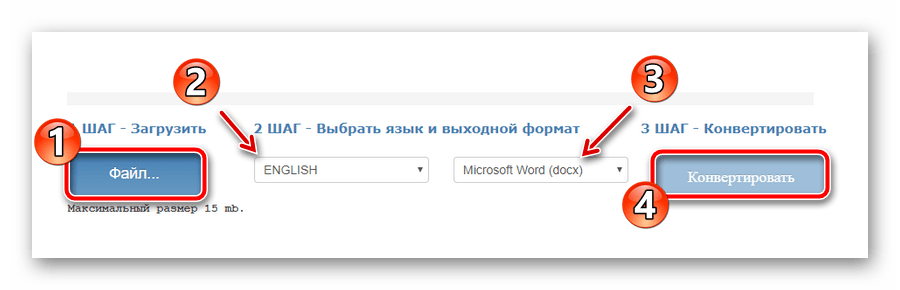
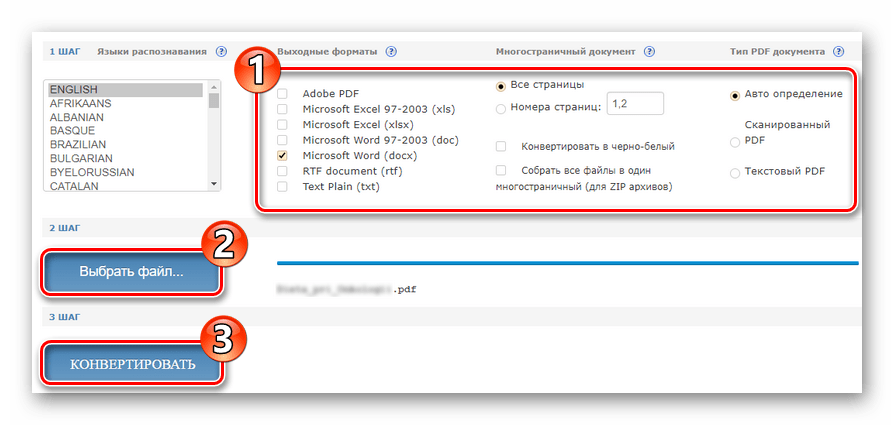
- Чтобы распознать текст из PDF как «гость», без авторизации на ресурсе, воспользуйтесь соответствующей формой на главной странице сайта.

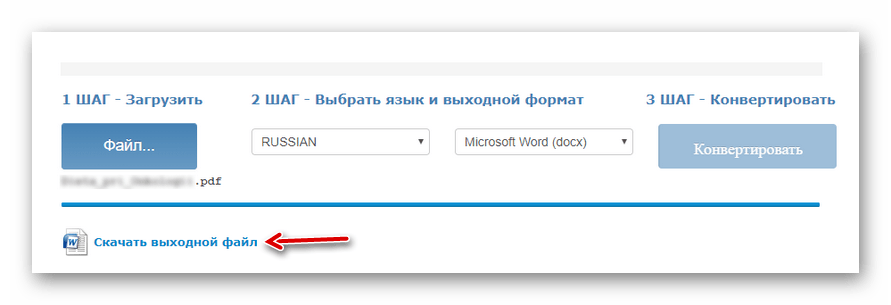
Выберите нужный документ с помощью кнопки «Файл», укажите основной язык текста, выходной формат, затем дождитесь загрузки файла и нажмите «Конвертировать». - По окончании процесса оцифровки нажмите «Скачать выходной файл» для сохранения готового документа с текстом на компьютере.

Для авторизованных же пользователей последовательность действий несколько иная.
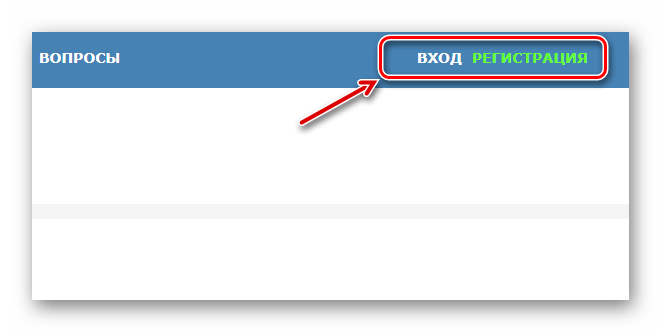
- Воспользуйтесь кнопкой «Регистрация» или «Вход» в верхней панели меню, чтобы, соответственно, создать учетную запись Free Online OCR либо зайти в нее.

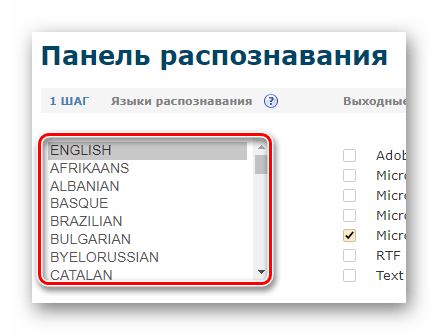
- После авторизации в панели распознавания, удерживая клавишу «CTRL», выберите до двух языков исходного документа из предложенного списка.

- Укажите дальнейшие параметры извлечения текста из PDF и нажмите кнопку «Выбрать файл» для загрузки документа в сервис.

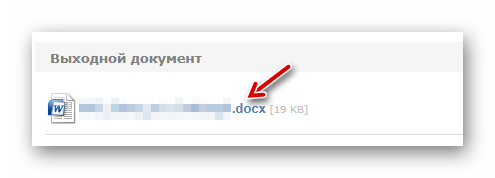
Затем, чтобы приступить к распознаванию, щелкните «Конвертировать». - По окончании обработки документа нажмите на ссылку с названием выходного файла в соответствующей колонке.

Результат распознавания сразу же будет сохранен в памяти вашего компьютера.
При необходимости извлечь текст из небольшого PDF-документа можно смело прибегать к использованию вышеописанного инструмента. Для работы же с объемными файлами придется купить дополнительные символы во Free Online OCR либо же прибегнуть к другому решению.
Способ 3: NewOCR
Полностью бесплатный OCR-сервис, позволяющий извлекать текст практически из любых графических и электронных документов вроде DjVu и PDF. Ресурс не накладывает ограничений на размер и количество распознаваемых файлов, не требует регистрации и предлагает широкий набор сопутствующих функций.
NewOCR поддерживает 106 языков и умеет корректно обрабатывать даже низкокачественные сканы документов. Есть возможность вручную выбирать область для распознавания текста на странице файла.
- Так, приступить к работе с ресурсом вы можете сразу, без необходимости выполнения лишних действий.

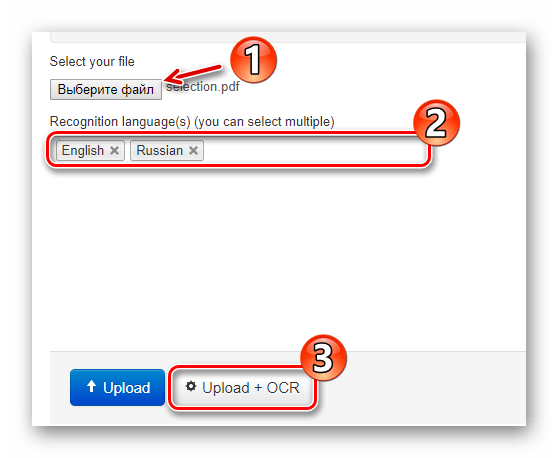
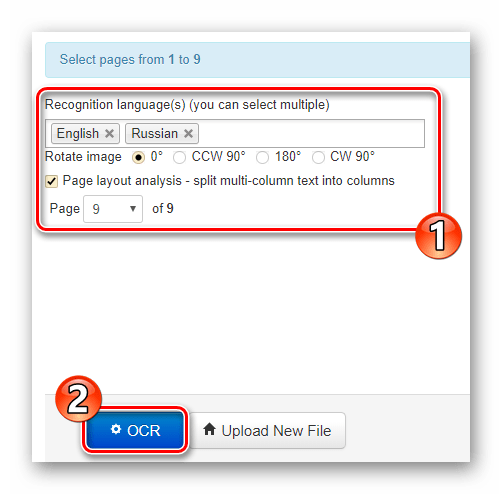
Прямо на главной странице размещена форма для импорта документа на сайт. Чтобы загрузить файл в NewOCR, воспользуйтесь кнопкой «Выберите файл» в разделе «Select your file». Затем в поле «Recognition language(s)» укажите один или более языков исходного документа, после чего нажмите «Upload + OCR». - Задайте предпочитаемые настройки распознавания, выберите нужную страницу для извлечения текста и щелкните по кнопке «OCR».

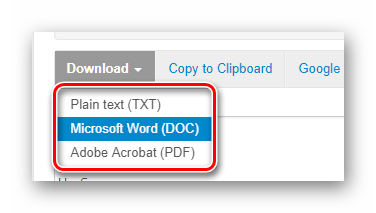
- Прокрутите страницу немного ниже и найдите кнопку «Download».

Щелкните по ней и в выпадающем списке выберите необходимый формат документа для скачивания. После этого готовый файл с извлеченным текстом будет загружен на ваш компьютер.
Инструмент удобный и достаточно качественно распознает все символы. Впрочем, обработку каждой страницы импортированного PDF-документа нужно запускать самостоятельно и выводится она в отдельный файл. Можно, конечно, сразу копировать результаты распознавания в буфер обмена и объединять их с другими.
Тем не менее, учитывая вышеописанный нюанс, большие объемы текста с помощью NewOCR извлекать весьма затруднительно. С малыми же файлами сервис справляется «на ура».
Способ 4: OCR.Space
Простой и понятный ресурс для оцифровки текста, позволяет распознавать PDF-документы и выводить результат в TXT-файл. Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
- Регистрироваться для работы с инструментом не нужно.

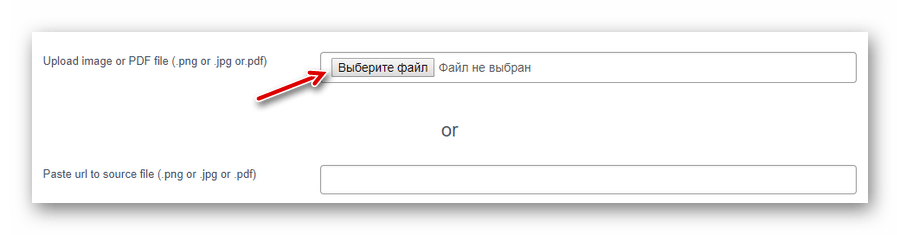
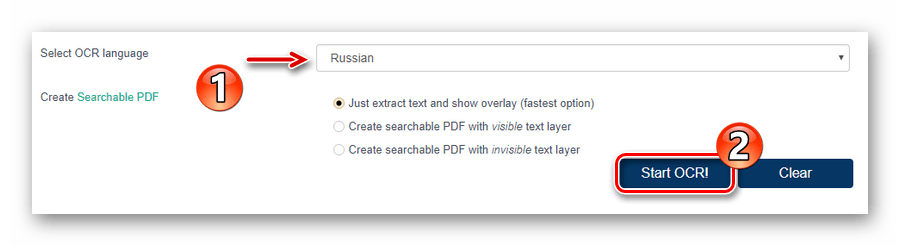
Просто перейдите по ссылке выше и загрузите PDF-документ на сайт с компьютера при помощи кнопки «Выберите файл» либо из сети — по ссылке. - В выпадающем списке «Select OCR language» выберите язык импортированного документа.

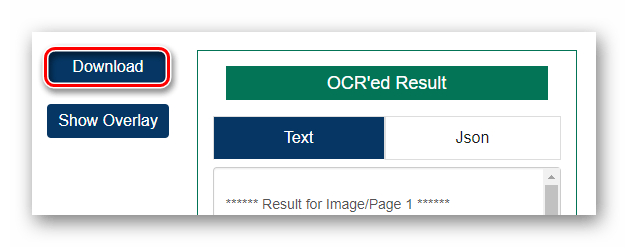
Затем запустите процесс распознавания текста, щелкнув по кнопке «Start OCR!». - По окончании обработки файла ознакомьтесь с результатом в поле «OCR’ed Result» и нажмите «Download», чтобы скачать готовый TXT-документ.

Если вам нужно просто извлечь текст из PDF и при этом финальное его форматирование совсем не важно, OCR.Space — хороший выбор. Единственное, документ должен быть «одноязычным», так как распознавание двух и более языков одновременно в сервисе не предусмотрено.
Читайте также: Бесплатные аналоги FineReader
Оценивая онлайн-инструменты, представленные в статье, следует отметить, что наиболее точно и качественно с функцией OCR справляется FineReader Online от ABBYY. Если для вас важна именно максимальная точность распознавания текста, лучше всего рассмотреть конкретно этот вариант. Но и заплатить за него, скорее всего, также придется.
Если же нужна оцифровка небольших документов и вы готовы самостоятельно исправлять ошибки за сервисом, целесообразно использовать NewOCR, OCR.Space или Free Online OCR.
Рекомендуем:
 Лучшие приложения для просмотра ТВ каналов на Андроид
Лучшие приложения для просмотра ТВ каналов на Андроид
 7 лучших расширений для блокировки рекламы в Google Chrome
7 лучших расширений для блокировки рекламы в Google Chrome
 Как почистить кэш и куки в Яндекс браузере
Как почистить кэш и куки в Яндекс браузере
 Как узнать температуру процессора в Windows 10
Как узнать температуру процессора в Windows 10








Тоже помогло, спасибо!