 lumpics.ru
lumpics.ruВсе способы:
В последнее время можно все чаще столкнуться с ситуацией, когда нужно перевести какой-либо текст, содержащийся на изображениях, в электронную текстовую форму. Для того чтобы сэкономить время и не перепечатывать вручную, следует использовать специальные компьютерные приложения для распознавания текста, о чем мы и расскажем сегодня.
Как оцифровать текст
На рынке представлено немало приложений для оцифровки текста, поэтому каждый пользователь найдёт решение, соответствующее требованиям.
Способ 1: ABBYY FineReader
Это условно-бесплатное приложение от российского разработчика обладает огромнейшим функционалом и позволяет не только распознавать текст, но и производить его редактирование, сохранение в различных форматах и сканирование бумажных исходников.
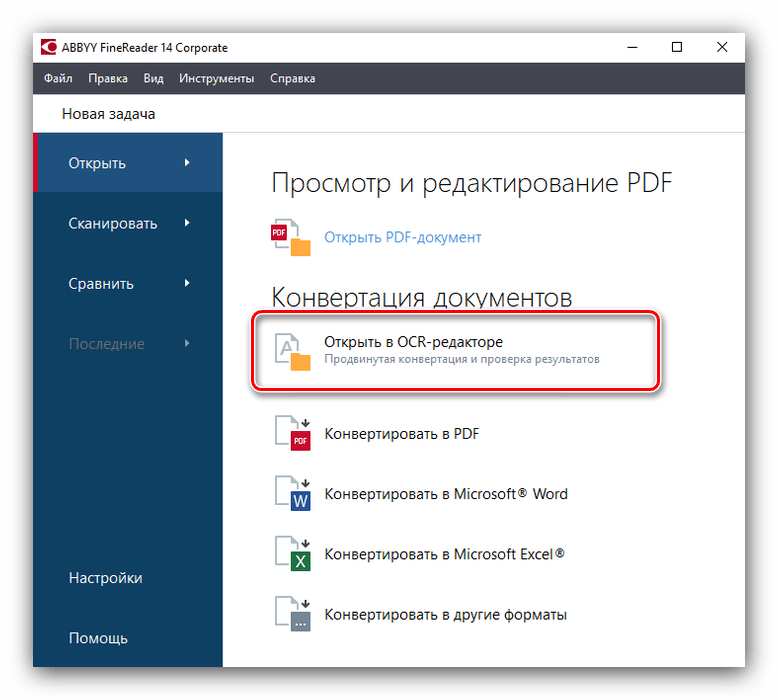
- Чтобы распознать текст на картинке, прежде всего, нужно загрузить её в программу. Для этого после запуска ABBYY FineReader жмем на кнопку «Открыть в OCR редакторе».

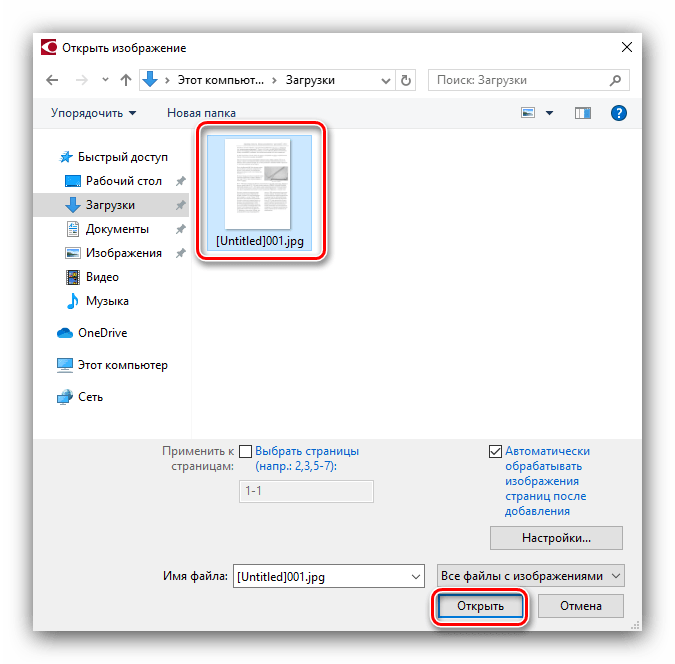
После выполнения данного действия открывается окно выбора источника, где вы должны найти и открыть нужное изображение. Поддерживаются следующие популярные форматы: JPEG, PNG, GIF, TIFF, XPS, BMP и др., а также файлы PDF и DjVU.
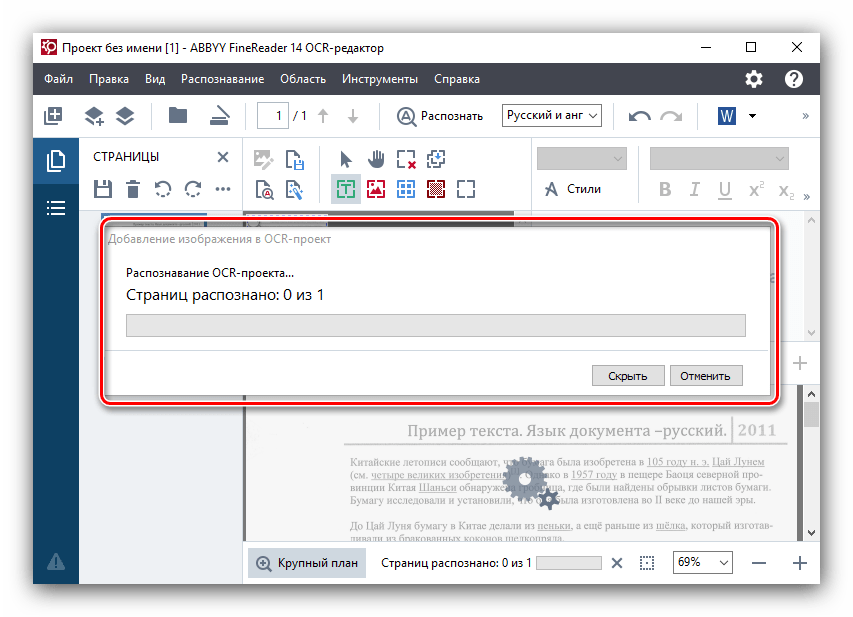
- После загрузки в ABBYY FineReader автоматически начинается процесс распознавания текста на картинке без вашего вмешательства.

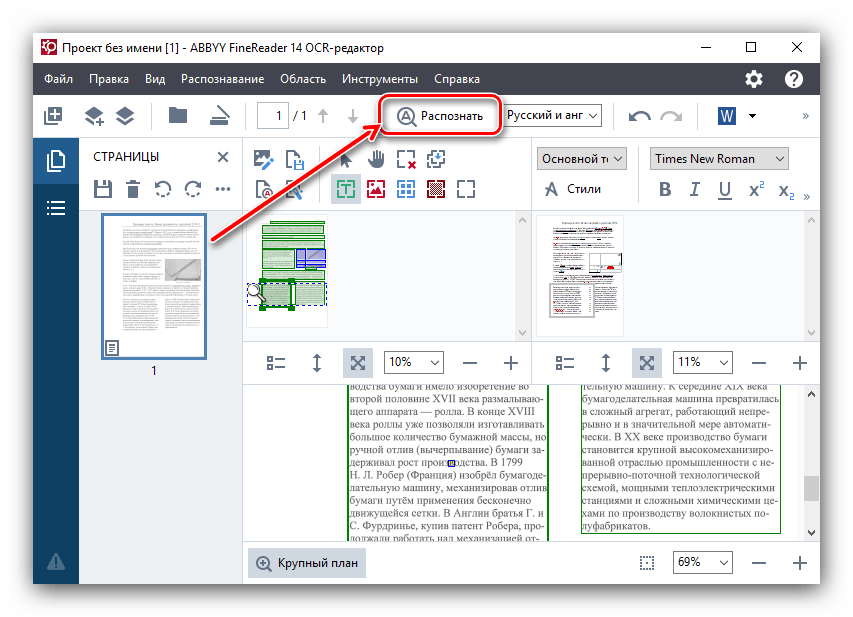
В случае если вы хотите произвести повторную процедуру распознавания, достаточно просто нажать кнопку «Распознать» в верхнем меню. - Иногда не все символы программа может распознать корректно. Это может быть в том случае, если изображение на исходнике не слишком качественное, очень мелкий шрифт, в тексте используется несколько разных языков, применяются нестандартные символы. Но это не беда, так как ошибки можно исправить вручную, с помощью текстового редактора и набора инструментов, которые в нем содержатся.
Для облегчения поиска неточностей оцифровки программа по умолчанию выделяет возможные ошибки бирюзовым цветом.
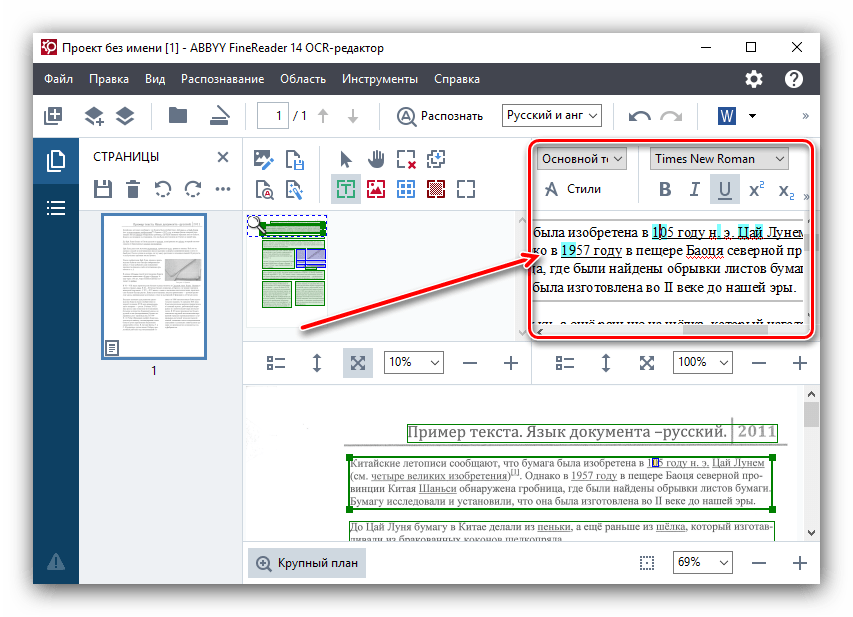
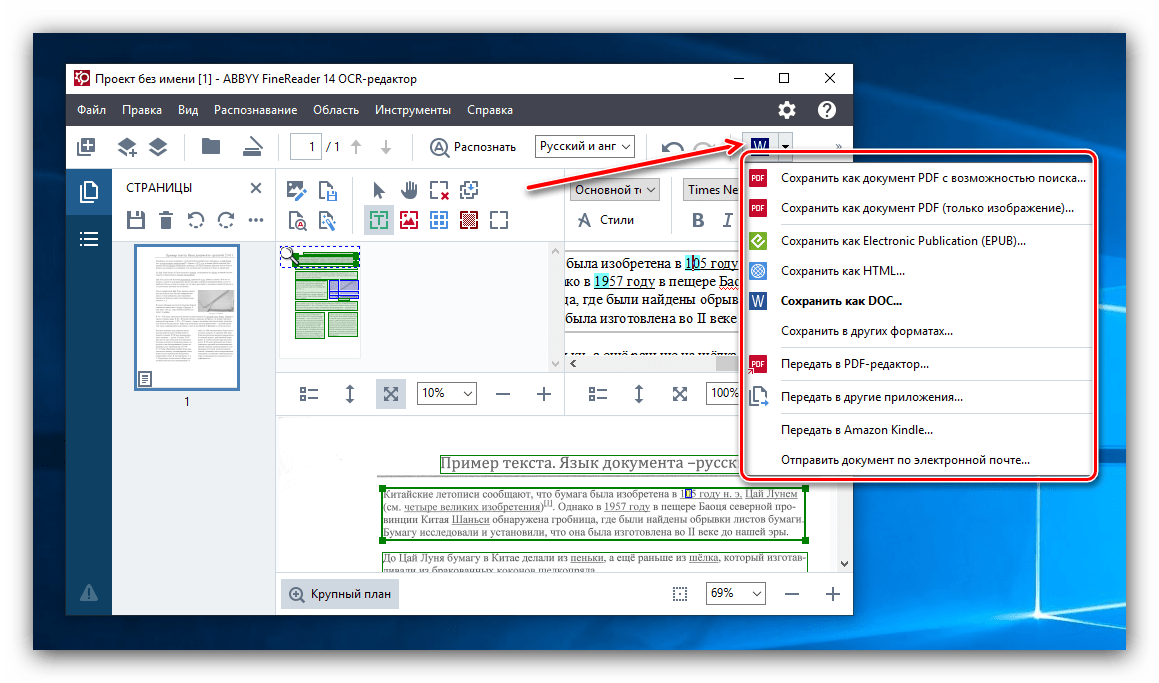
- Закономерным окончанием процесса распознавания является сохранение его результатов. Для этого жмем кнопку «Сохранить» на верхней панели меню. По умолчанию она имеет вид иконки старого логотипа Microsoft Word. Перед нами появляется окно, где можно самостоятельно определить будущее местонахождение, в котором будет располагаться файл с распознанным текстом, а также его формат. Доступны следующие варианты для сохранения: DOC, DOCX, RTF, PDF, ODT, HTML, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, DjVU.
ABBYY FineReader представляет собой самое продвинутое решение, но однозначно рекомендовать именно его мешают платная модель распространения и ограничения пробной версии.
Способ 2: Readiris
Приложение Readiris укрепилось на рынке как ближайший конкурент упомянутого выше Файн Ридер – оно предоставляет подобный функционал, некоторые аспекты исполняет несколько лучше, чем продукция ABBYY.
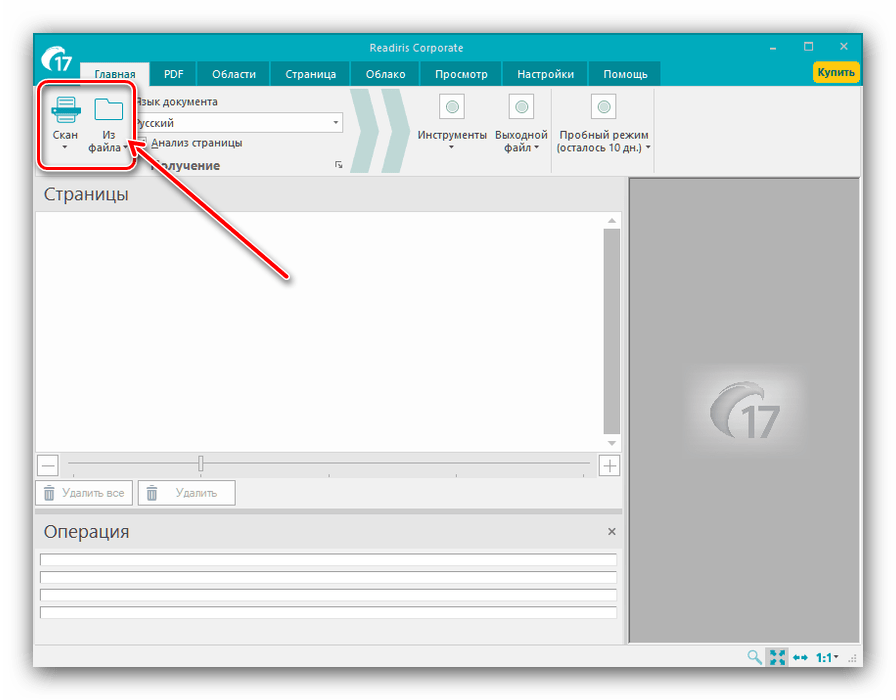
- После запуска приложения выберите источник данных для оцифровки – со сканера или же с готового графического файла.

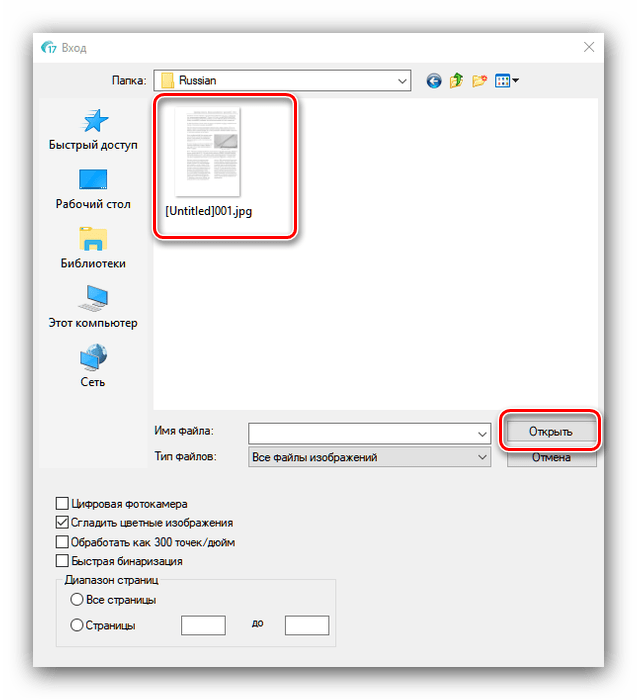
В примере мы будем использовать последний вариант – для него следует воспользоваться кнопкой «Из файла». - Откроется диалоговое окно «Проводника», в котором следует выбрать нужные документы. Поддерживается большинство графических форматов, а также PDF.
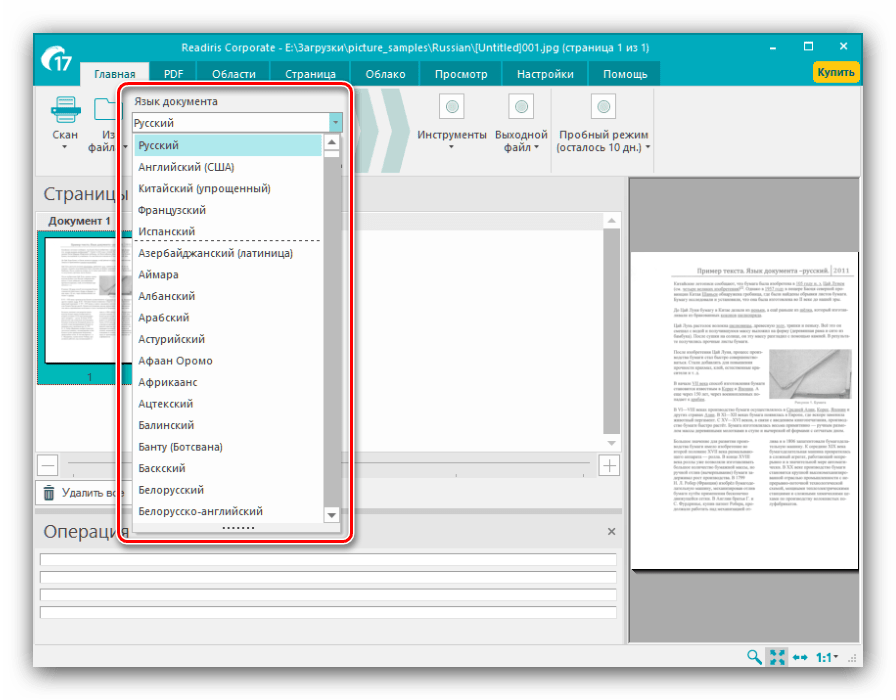
- Подождите, пока документ будет загружен в программу, после чего следует настроить распознавание текста. Первым делом нужно установить основной язык – выберите его из выпадающего меню.
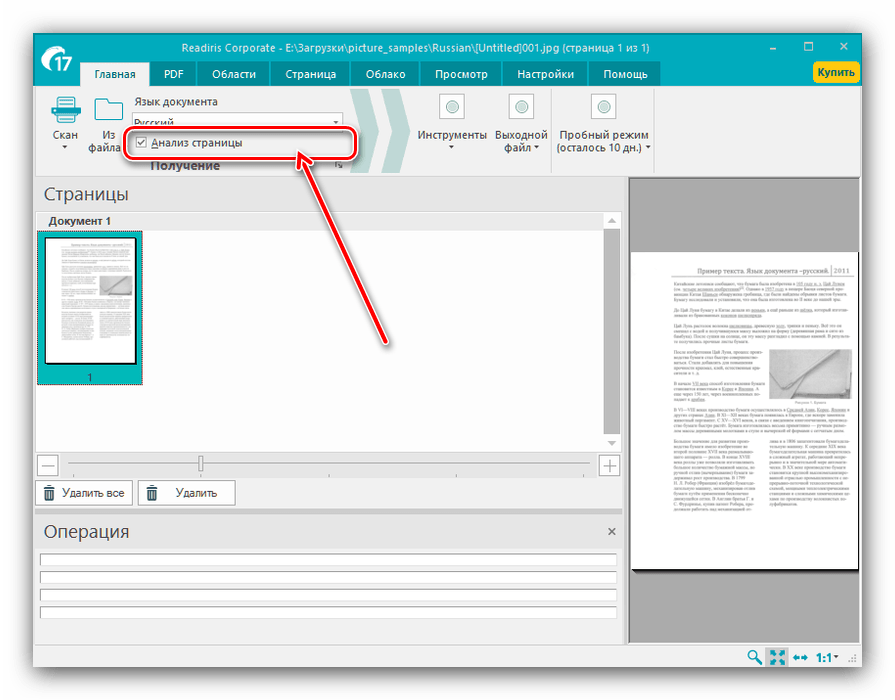
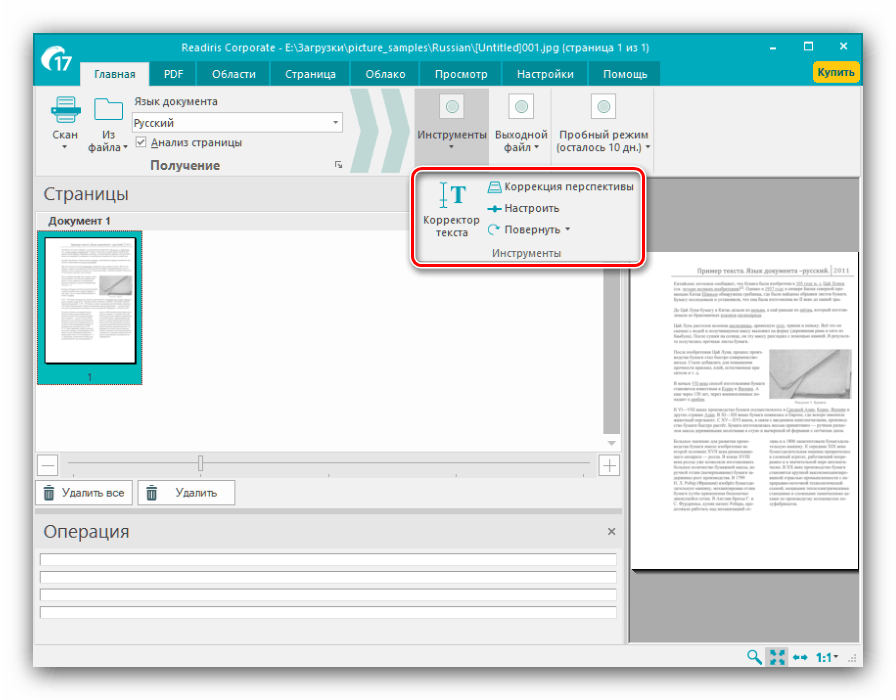
Также рекомендуем отметить опцию «Анализ текста», благодаря которой значительно повыситься качество оцифровки. - Далее обратитесь к меню «Инструменты» — имеющиеся в нём параметры помогут решить некоторые проблемы сканирования, такие как искажение перспективы, недостаточная контрастность картинки или смещение текста относительно полотна.
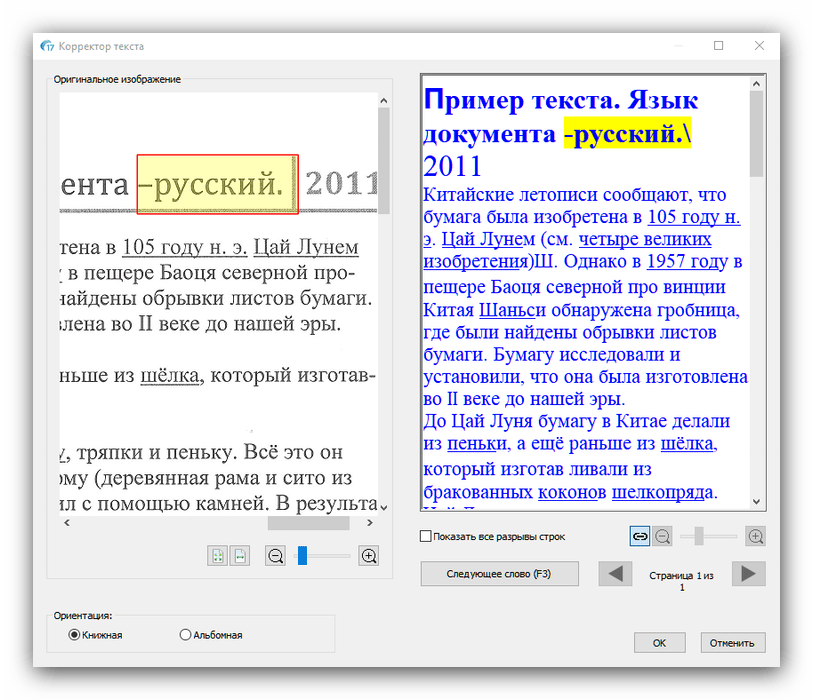
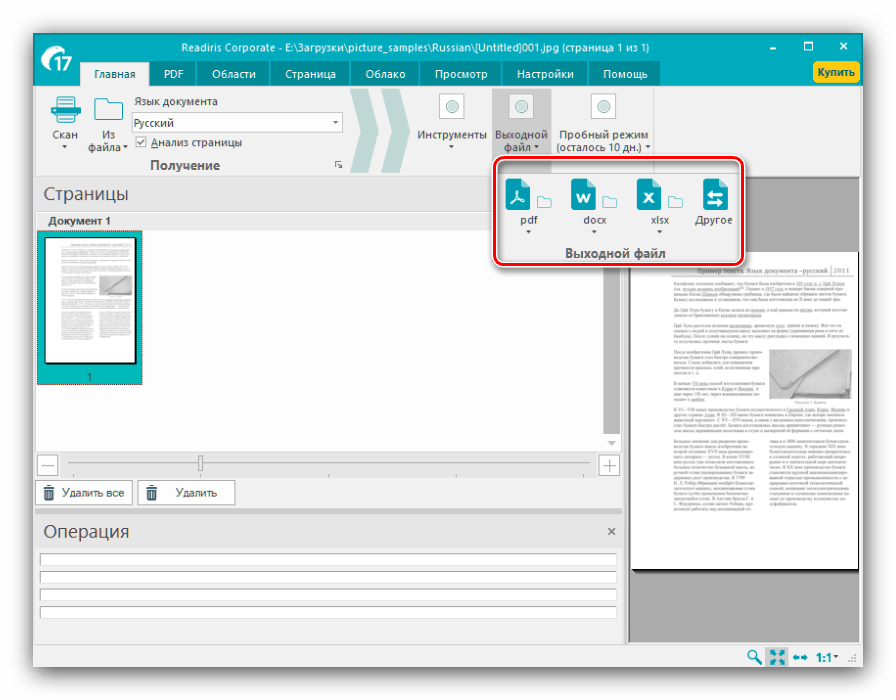
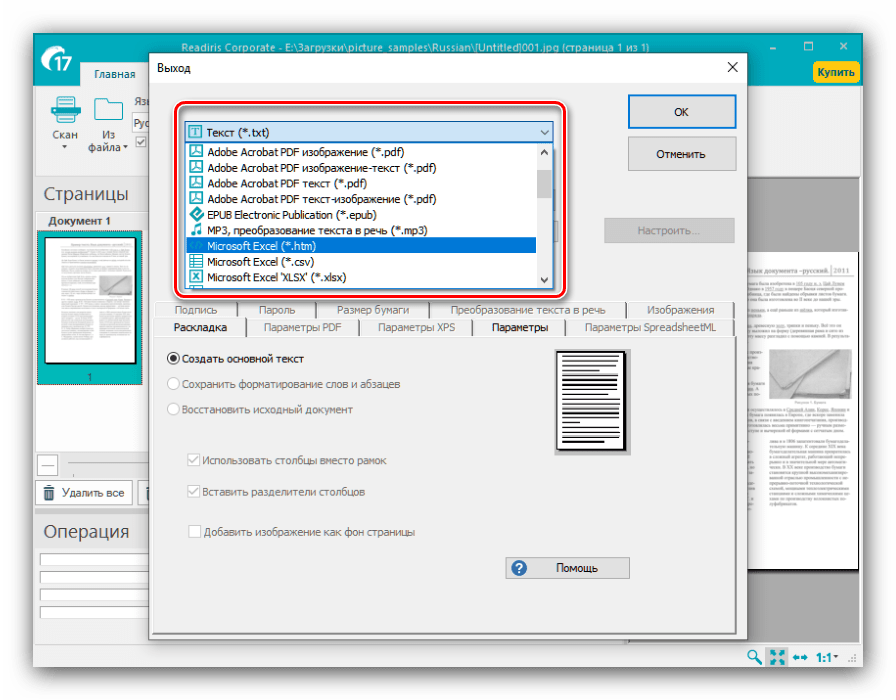
Из этого меню также можно подкорректировать текст, если распознавание сработало неправильно. - После внесения изменений в распознанный текст следует задать выходной формат полученных данных через одноименное меню в панели инструментов. Основными форматами считаются PDF, а также файлы Microsoft Office (DOCX и XLSX) – кликните по требуемой позиции для выбора.
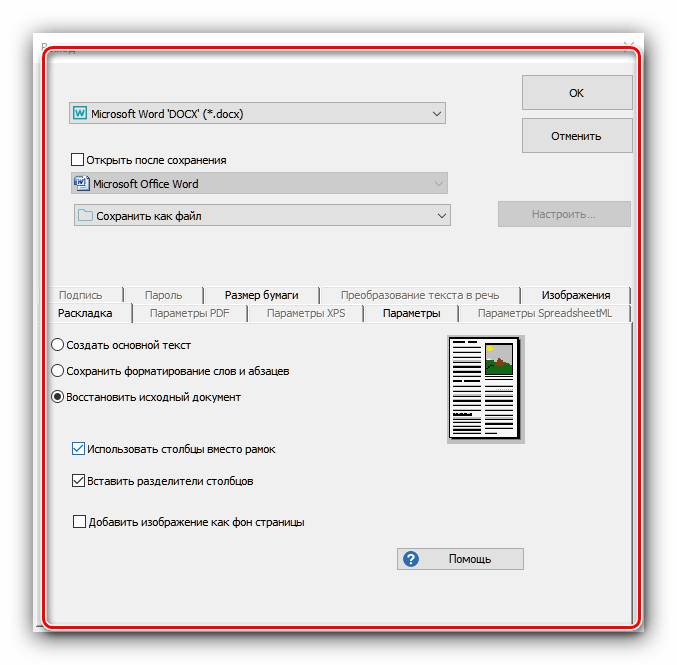
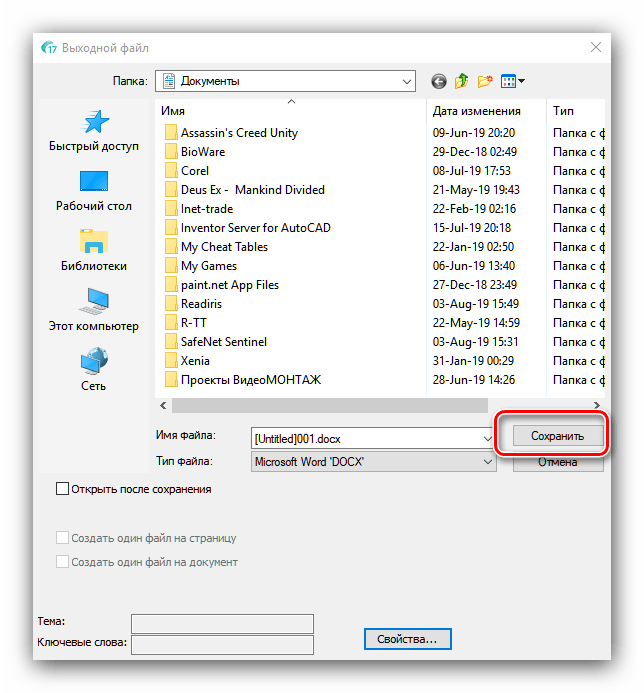
Все возможные форматы экспорта сгруппированы в пункте «Другое». Кроме упомянутых выше типов файлов, оцифрованный текст можно сохранить в виде данных OpenOffice, гипертекстовых файлов или обычных TXT. - После выбора формата откроется окошко Мастера по экспорту. В нём можно настроить те или иные параметры полученного файла (зависят от выбранного формата) и вариант сохранения (локальный или в облачный сервис). После внесения всех требуемых изменений нажмите «ОК».

Снова появится окно «Проводника», в котором следует выбрать желаемый конечный каталог сохранения.
В целом Readiris представляет собой удобное и современное решение для оцифровки текста, однако весомым его недостатком можно назвать платную модель распространения.
Способ 3: RiDoc
Ещё одно приложение, ориентированное на работу со сканерами, однако умеющее работать и с локальными файлами в разных форматах.
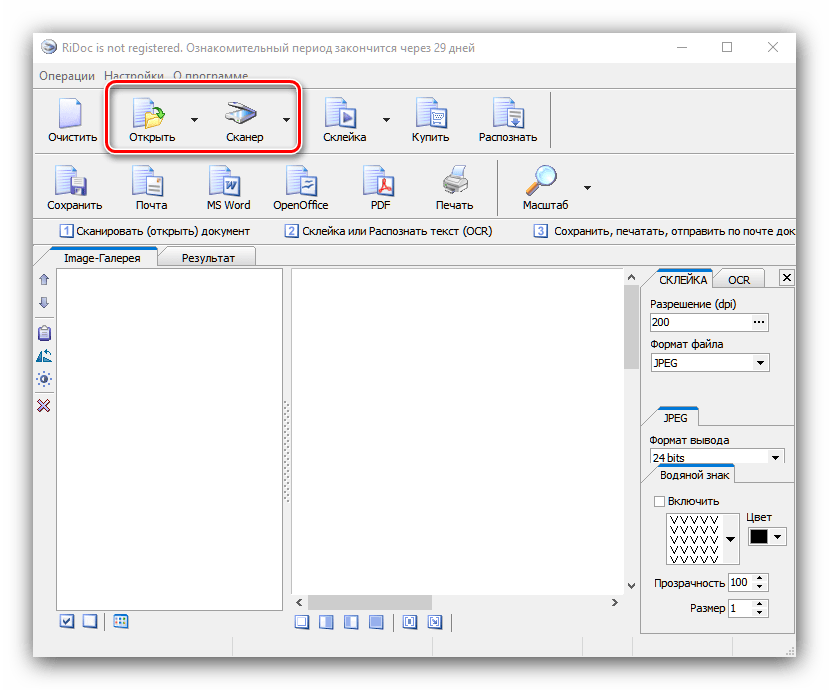
- Откройте приложение. Для начала работы используйте на панели инструментов кнопки «Открыть» или «Сканер» – первая отвечает за распознавание текста в локальных файлах, вторая позволяет начать оцифровку одновременно со сканированием. Для примера будем использовать первый вариант.
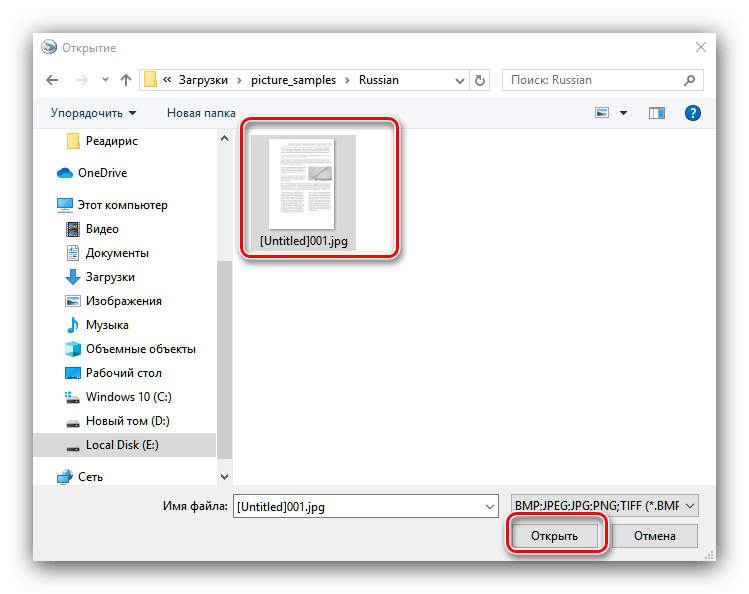
- В окне «Проводника» перейдите к документу, из которого требуется получить текст, и выберите его. Доступна также пакетная обработка документов.
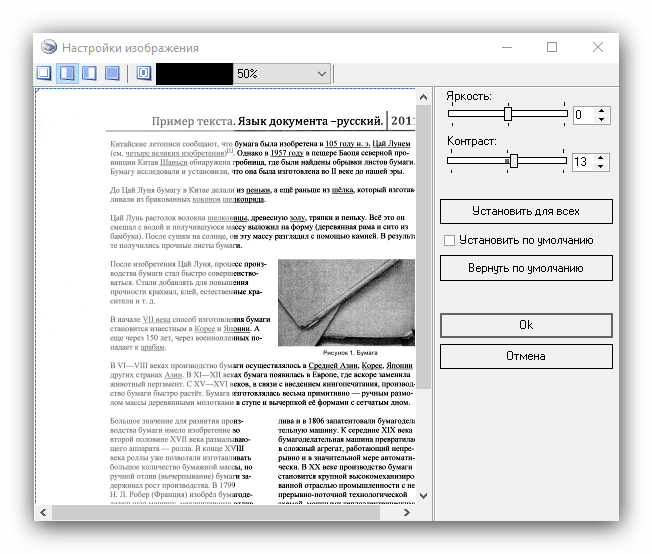
- Если требуется, можно обработать полученный файл: обрезать картинку, установить область распознавания, исправить огрехи сканирования.

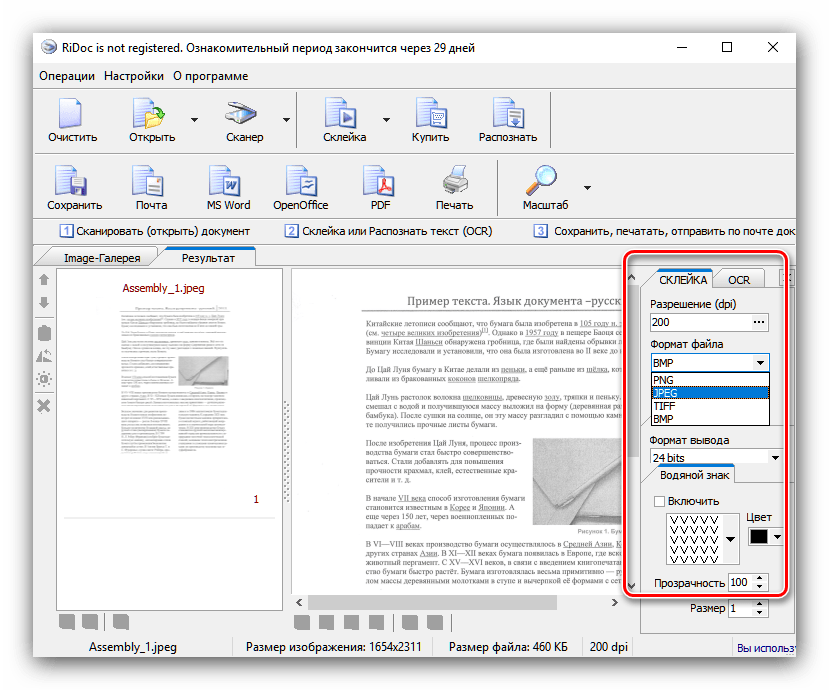
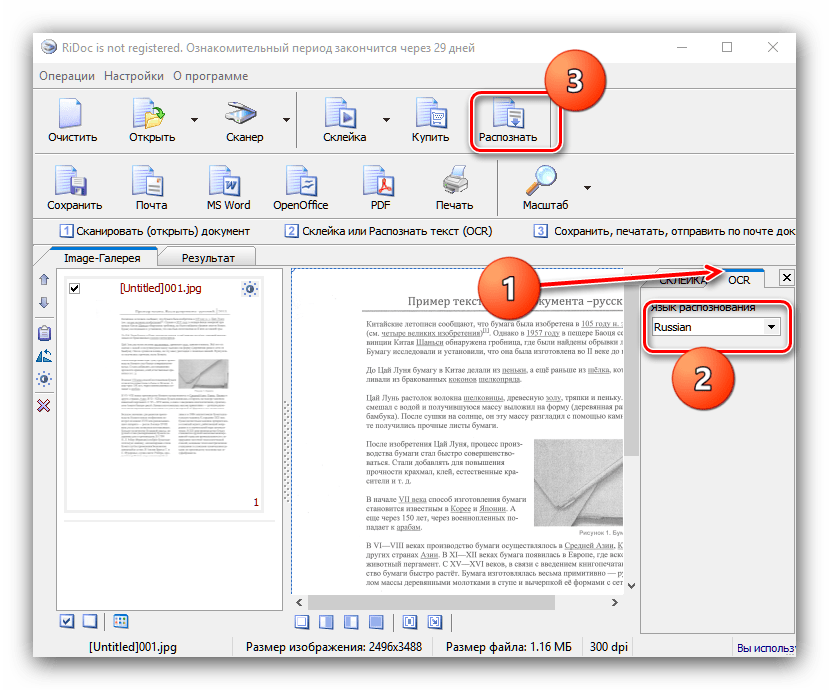
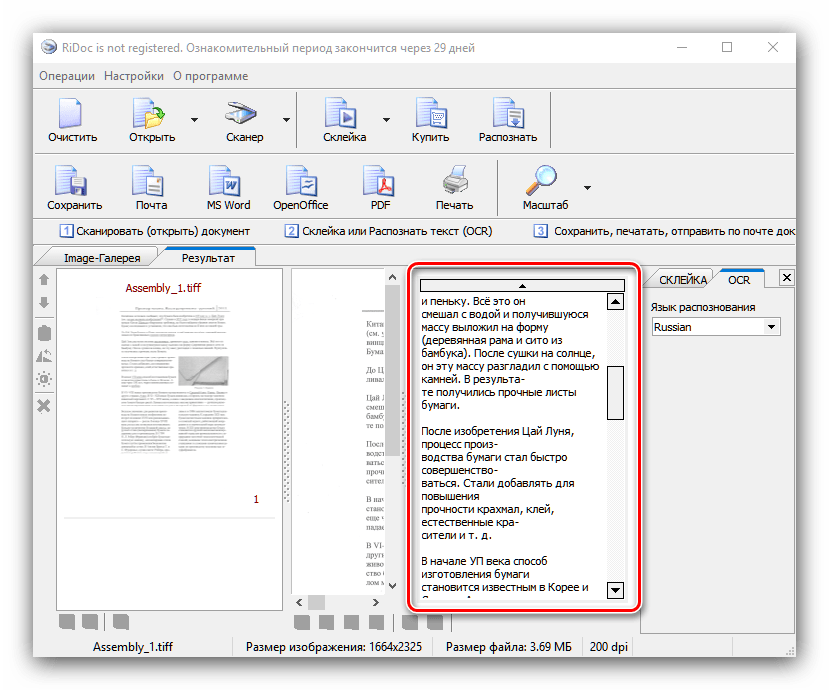
Отдельным пунктом стоит возможность склейки – в этом случае мультистраничный документ будет сохранён единым файлом. Можно выбрать значение DPI и формат вывода (доступны только файлы изображений). - Для распознавания текста в правой части окна найдите вкладку «OCR» и откройте её. Доступных опций не много – можно выбрать только язык документа. После смены пакета нажмите на кнопку «Распознать» на панели инструментов.

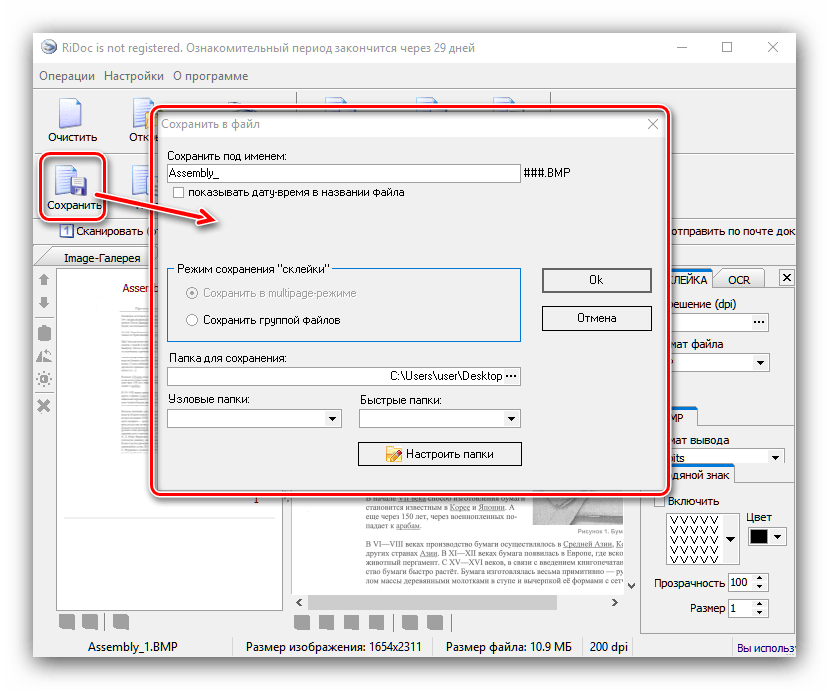
Отсюда же можно подправить результаты оцифровки. - Сохранение документов доступно в двух вариантах – прямое или экспорт в офисные приложения. Для выполнения первого способа следует использовать кнопку «Сохранить». Откроется окно, в котором можно выбрать место сохранения, а также тип (единичные файлы или один многостраничный). Формат сохраняемого файла зависит от выбранного на этапе склейки.
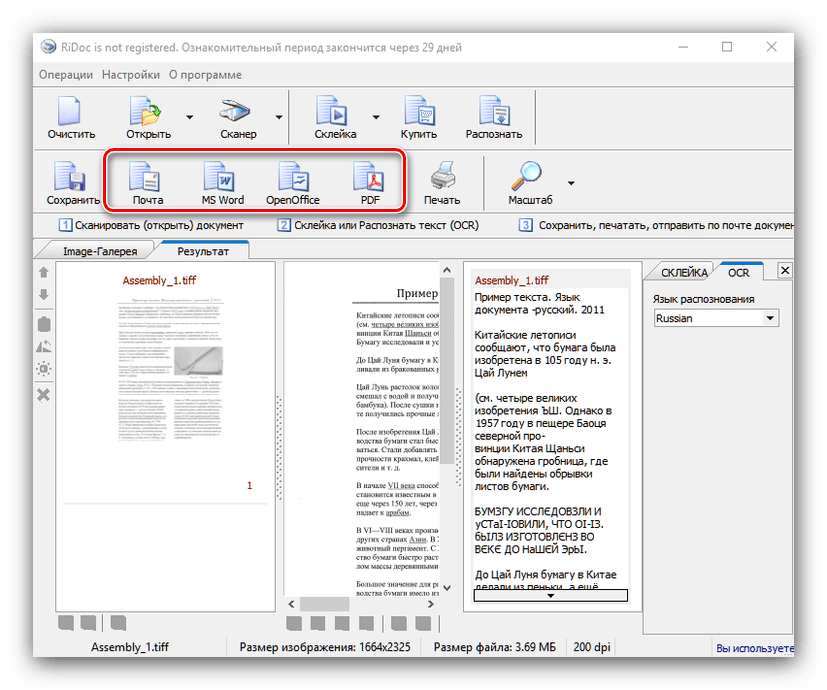
Экспорт результатов возможен в текстовые процессоры офисных пакетов Microsoft или OpenOffice, в виде электронного письма (кнопка «Почта»), в формат PDF или же печати на принтере. Для экспорта в офисные программы они должны быть установлены на компьютере, тогда как сохранение в ПДФ возможно даже без соответствующих приложений.
Как видим, РиДок представляет собой небогатое возможностями решение, но для несложных вариантов оцифровки вполне подойдёт.
Способ 4: Capture2Text
Небольшая утилита, которая позволяет распознавать текст из любой области на экране компьютера, полностью бесплатная и удобная в использовании.
Скачать Capture2Text с официального сайта
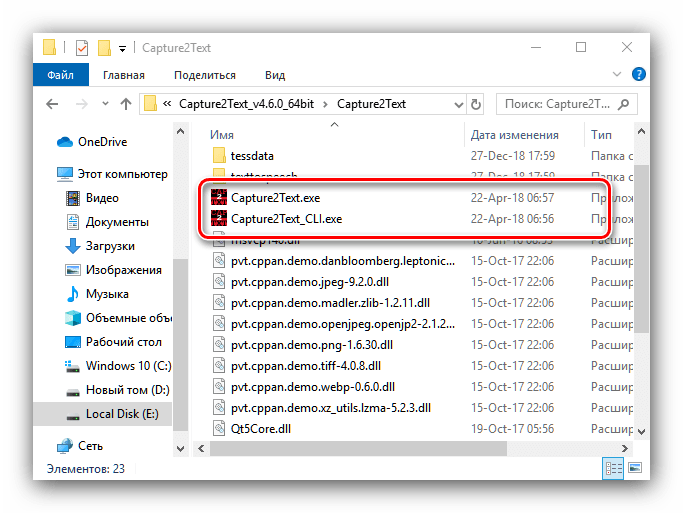
- Загрузите архив с программой и распакуйте его в любое удобное место. Затем перейдите к полученному каталогу и запустите исполняемый файл.

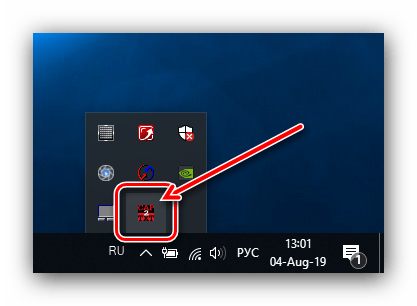
Далее откройте системный трей – в нём должна появится иконка утилиты.

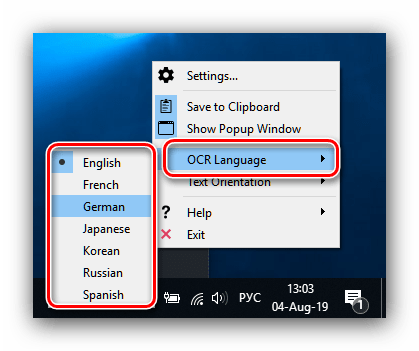
Для изменения языка распознавания кликните правой кнопкой мыши по значку Capture2Text в системном трее, затем в настройках выберите пункт «OCR Language» и установите нужный язык.
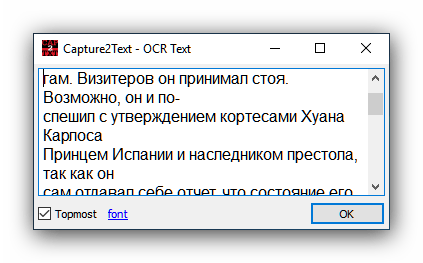
- Откройте файл, текст с которого требуется оцифровать, например, документ DjVU без текстового слоя. Когда файл будет открыт, нажмите сочетание клавиш Win+Q и выделите область распознавания.
- Появится окошко утилиты с результатами распознавания. Полученные данные можно скопировать в любое приложение, поддерживающее ввод пользовательского текста.

Приложение невероятно простое, но это оборачивается ограниченным функционалом и, порой, некорректным распознаванием русского текста. Также к недостаткам можем отнести отсутствие локализации на русский язык. Впрочем, для некоторых пользователей эти минусы несущественны, а основных возможностей будет вполне достаточно.
Способ 5: CuneiForm
Ещё одно решение для оцифровки текста, созданное на постсоветском пространстве. Несмотря на прекращение разработки, по-прежнему актуально.
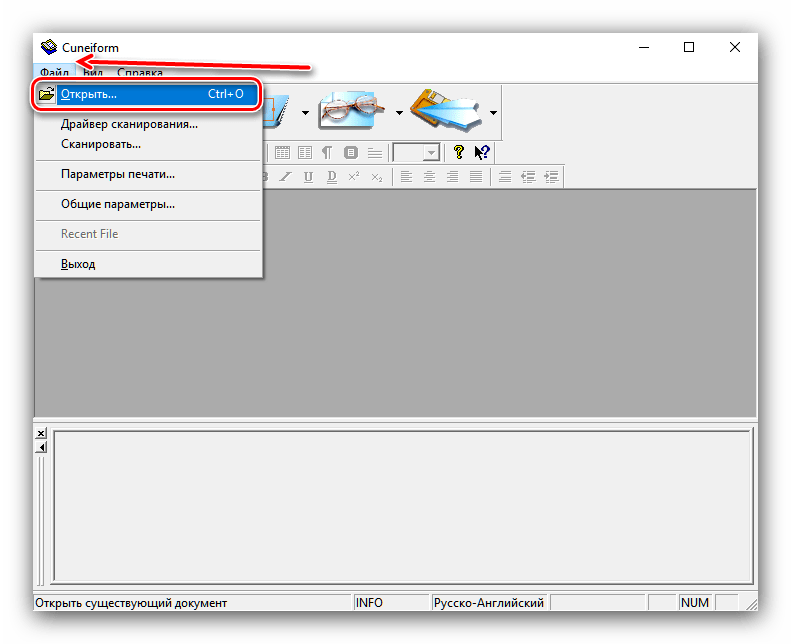
- Как и многие другие представленные в этой статье программы, КунейФорм умеет работать как с готовыми изображениями, так и получать данные напрямую со сканера. Воспользуемся первым вариантом – для этого откройте меню «Файл» и выберите в нём пункт «Открыть».
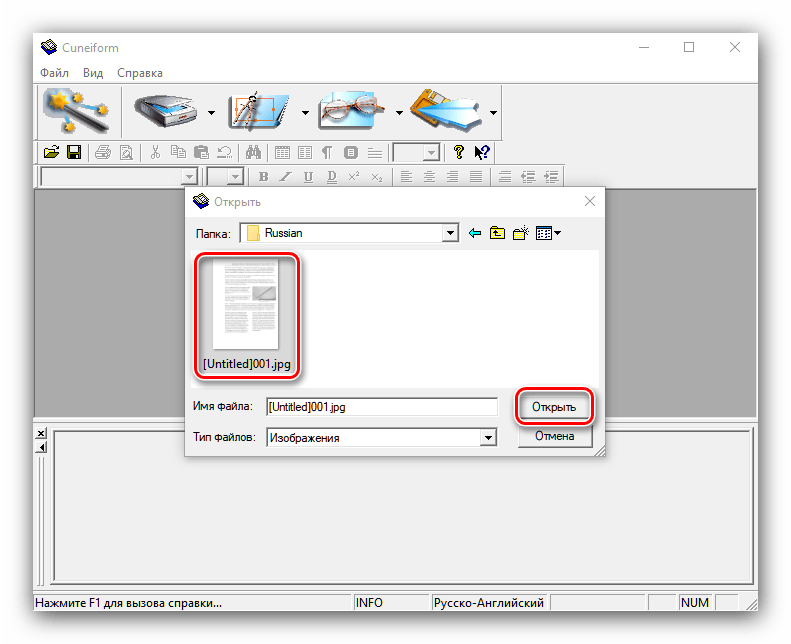
- Посредством «Проводника» выберите требуемый файл или файлы.
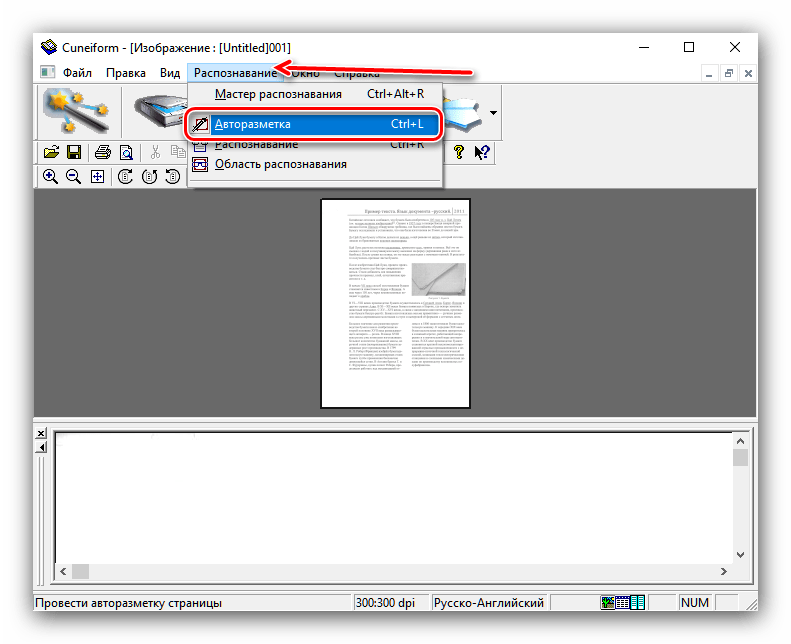
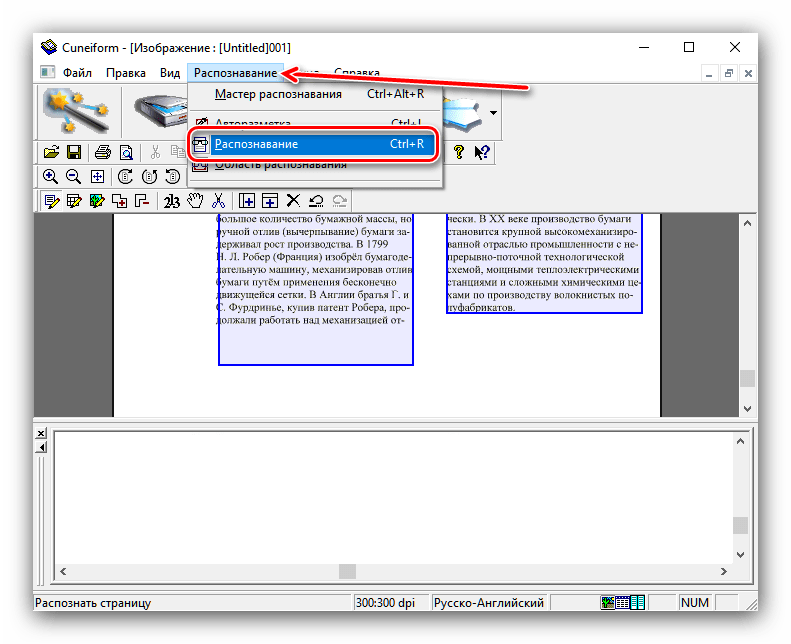
- После загрузки данных в программу используйте пункты «Распознавание» – «Авторазметка».

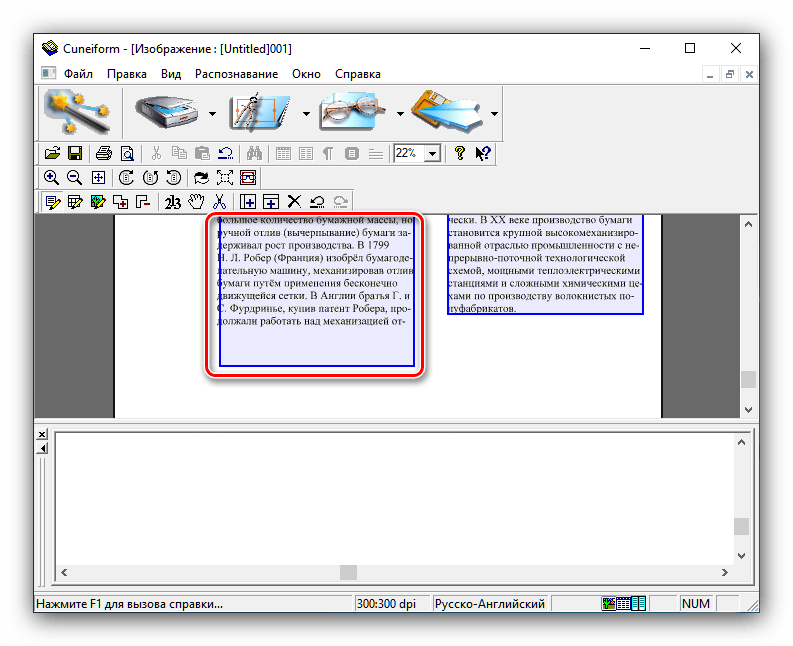
Это позволит выбрать области с текстом для более корректной работы модуля OCR. Если автоматические алгоритмы неправильно разметили страницу, области с текстом можно подправить вручную или вообще убрать. - Далее можно заниматься непосредственно оцифровкой. Снова откройте меню «Распознавание» и выберите вариант с таким же наименованием.
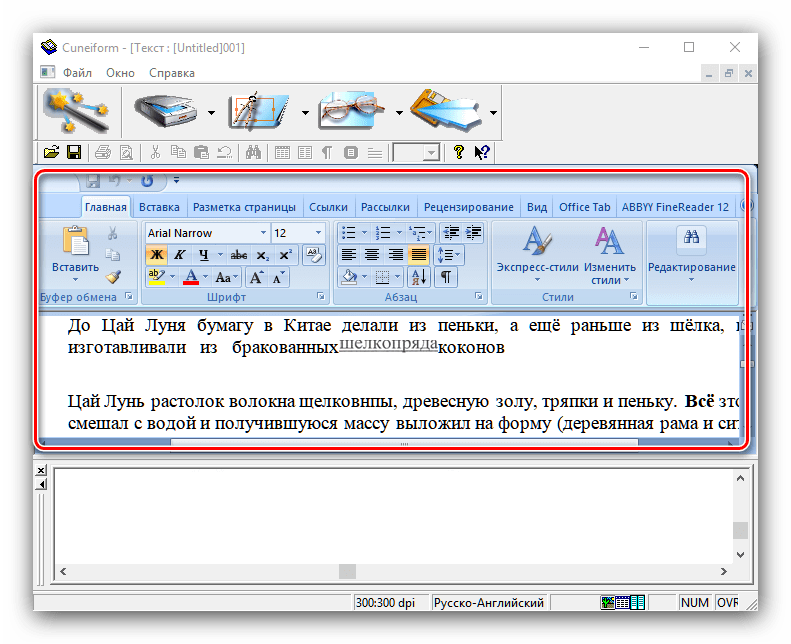
- Распознанный текст будет открыт в окне приложения, где его также можно редактировать. Возможности довольно обширные, и соответствуют полноценному текстовому редактору. В случае если на компьютере установлен MS Word, полученные данные будут открыты через его интерфейс.
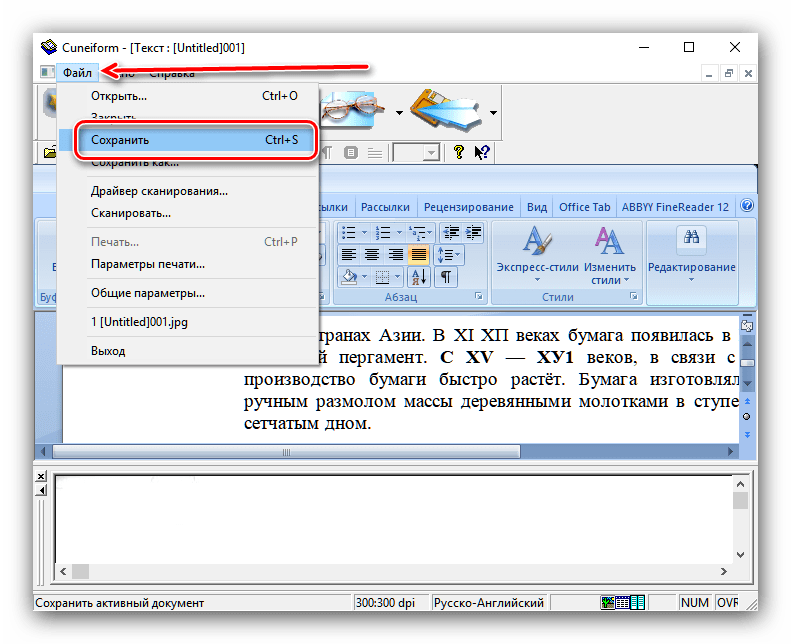
- Сохранение результатов работы доступно по пунктам «Файл» – «Сохранить».
В открывшемся «Проводнике» выберите местоположение полученного файла и его формат. Поддерживаются не много вариантов: TXT, RTF, внутренний формат FED, а также экспорт в приложения Microsoft Office (Word и Excel).
Как видим, CuneiForm представляет собой простой и в то же время мощный инструмент для оцифровки текста. Весомым его преимуществом будет свободная модель распространения, однако недостатки в виде окончания поддержки и отсутствия формата PDF могут заставить обратиться к альтернативам.
Заключение
Как видим, распознать текст с картинки довольно просто, если использовать для этого специализированные приложения. Данная процедура не потребует от вас много усилий, а польза будет в огромной экономии времени.
 Наша группа в TelegramПолезные советы и помощь
Наша группа в TelegramПолезные советы и помощь




нужно изображение tif преобразовать в документ pdf у меня не получилось