 lumpics.ru
lumpics.ruСодержание:
Способ 1: Использование автоматического инструмента
В Excel есть автоматический инструмент, предназначенный для разделения текста по столбцам. Он не работает в автоматическом режиме, поэтому все действия придется выполнять вручную, предварительно выбирая диапазон обрабатываемых данных. Однако настройка является максимально простой и быстрой в реализации.
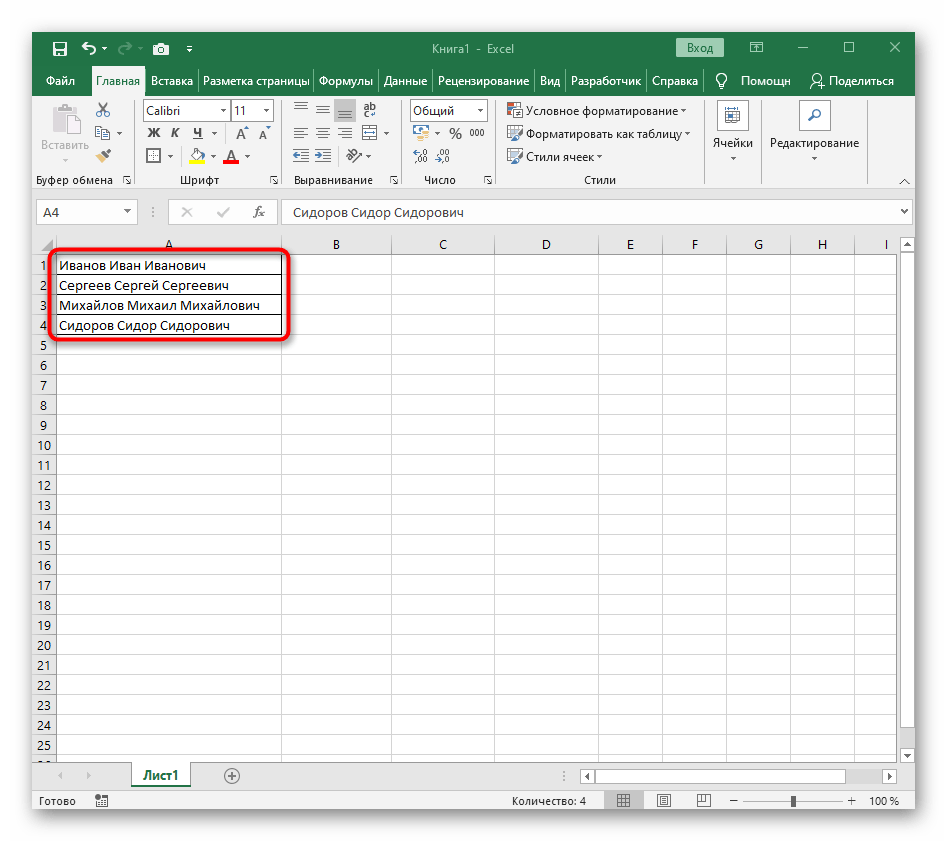
- С зажатой левой кнопкой мыши выделите все ячейки, текст которых хотите разделить на столбцы.
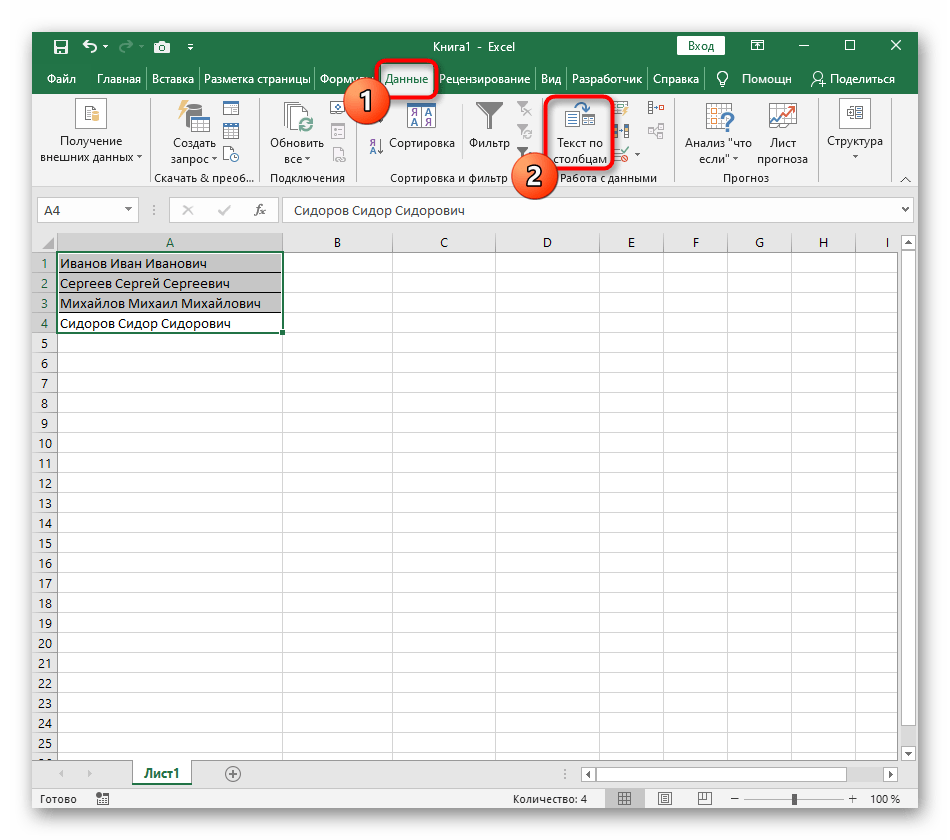
- После этого перейдите на вкладку «Данные» и нажмите кнопку «Текст по столбцам».
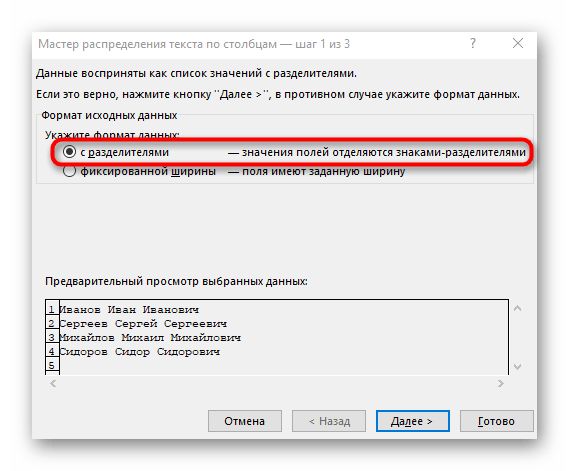
- Появится окно «Мастера разделения текста по столбцам», в котором нужно выбрать формат данных «с разделителями». Разделителем чаще всего выступает пробел, но если это другой знак препинания, понадобится указать его в следующем шаге.
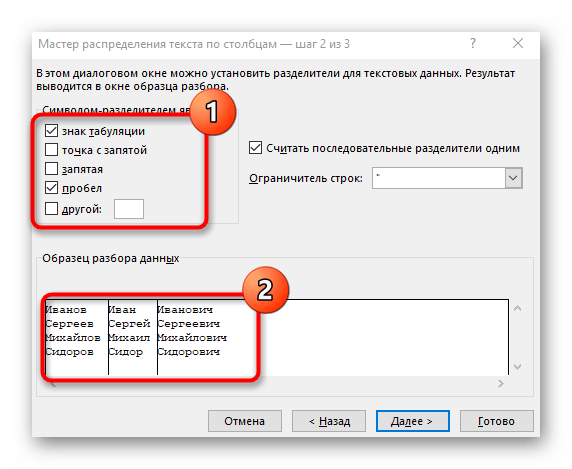
- Отметьте галочкой символ разделения или вручную впишите его, а затем ознакомьтесь с предварительным результатом разделения в окне ниже.
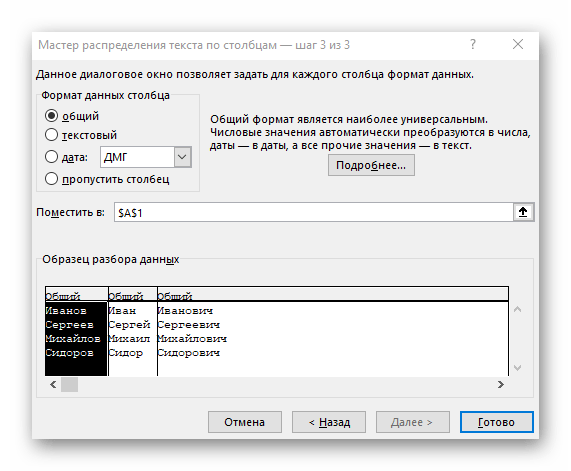
- В завершающем шаге можно указать новый формат столбцов и место, куда их необходимо поместить. Как только настройка будет завершена, нажмите «Готово» для применения всех изменения.
- Вернитесь к таблице и убедитесь в том, что разделение прошло успешно.
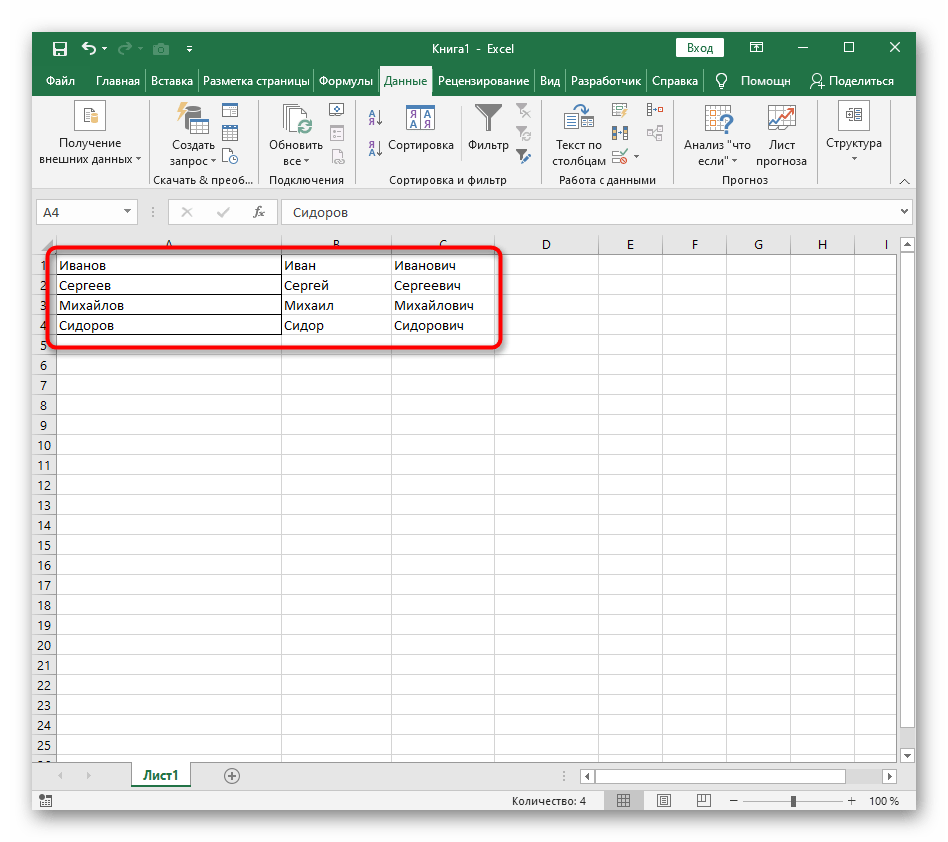
Из этой инструкции можно сделать вывод, что использование такого инструмента оптимально в тех ситуациях, когда разделение необходимо выполнить всего один раз, обозначив для каждого слова новый столбец. Однако если в таблицу постоянно вносятся новые данные, все время разделять их таким образом будет не совсем удобно, поэтому в таких случаях предлагаем ознакомиться со следующим способом.
Способ 2: Создание формулы разделения текста
В Excel можно самостоятельно создать относительно сложную формулу, которая позволит рассчитать позиции слов в ячейке, найти пробелы и разделить каждое на отдельные столбцы. В качестве примера мы возьмем ячейку, состоящую из трех слов, разделенных пробелами. Для каждого из них понадобится своя формула, поэтому разделим способ на три этапа.
Шаг 1: Разделение первого слова
Формула для первого слова самая простая, поскольку придется отталкиваться только от одного пробела для определения правильной позиции. Рассмотрим каждый шаг ее создания, чтобы сформировалась полная картина того, зачем нужны определенные вычисления.
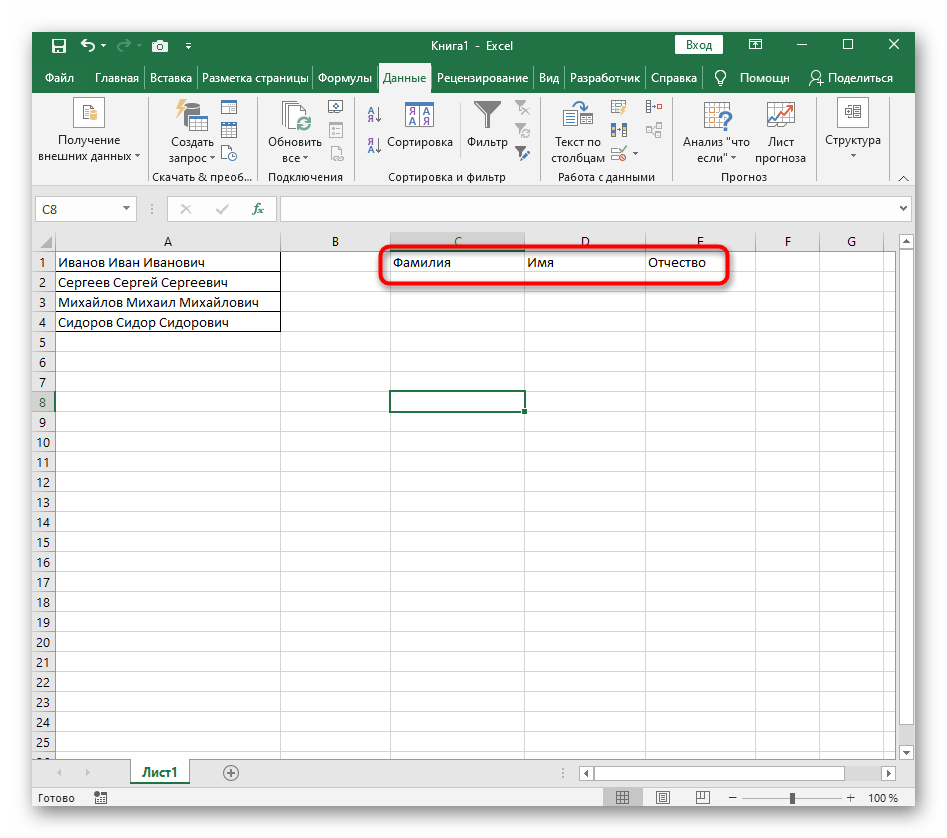
- Для удобства создадим три новые столбца с подписями, куда будем добавлять разделенный текст. Вы можете сделать так же или пропустить этот момент.
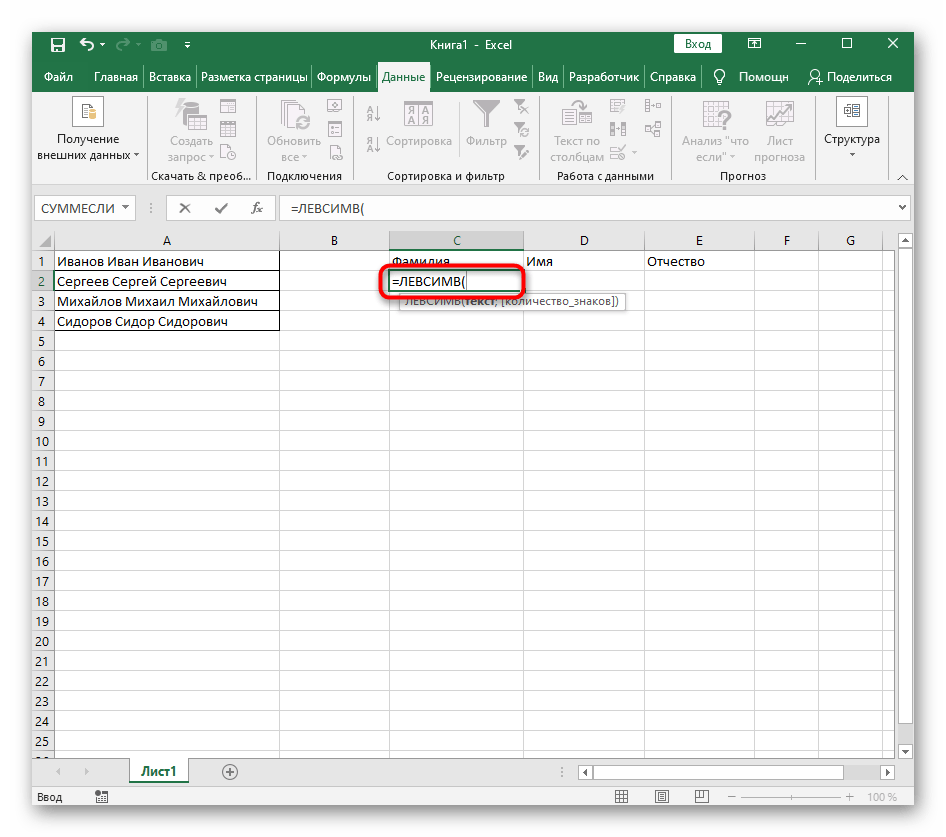
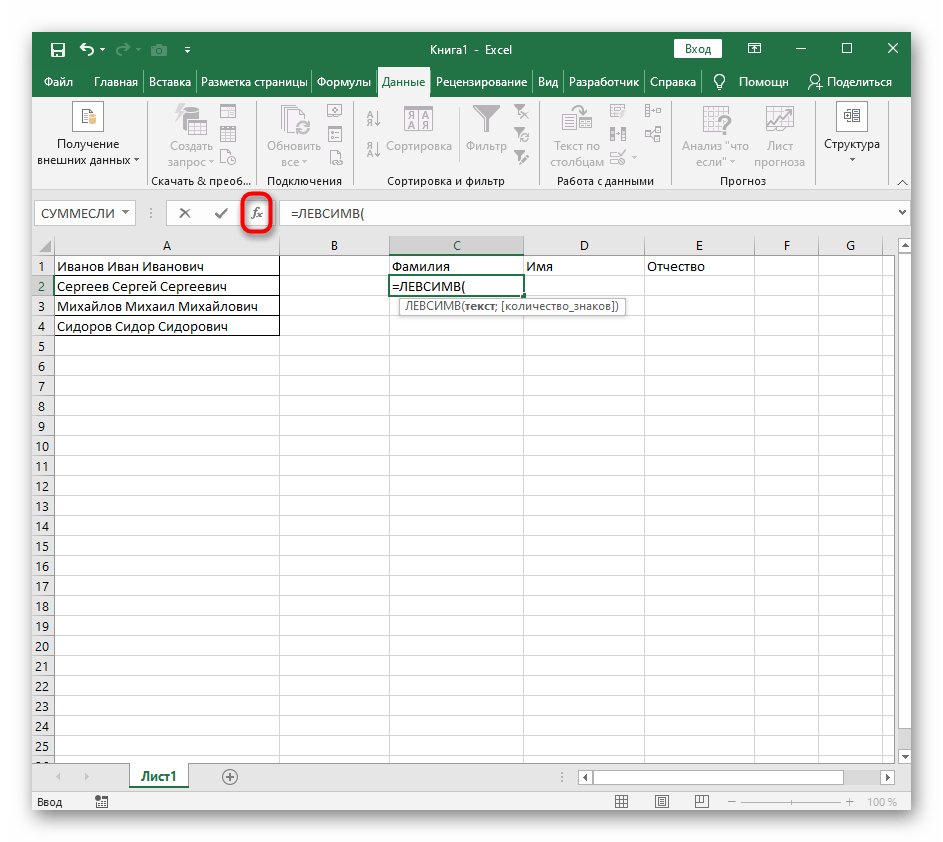
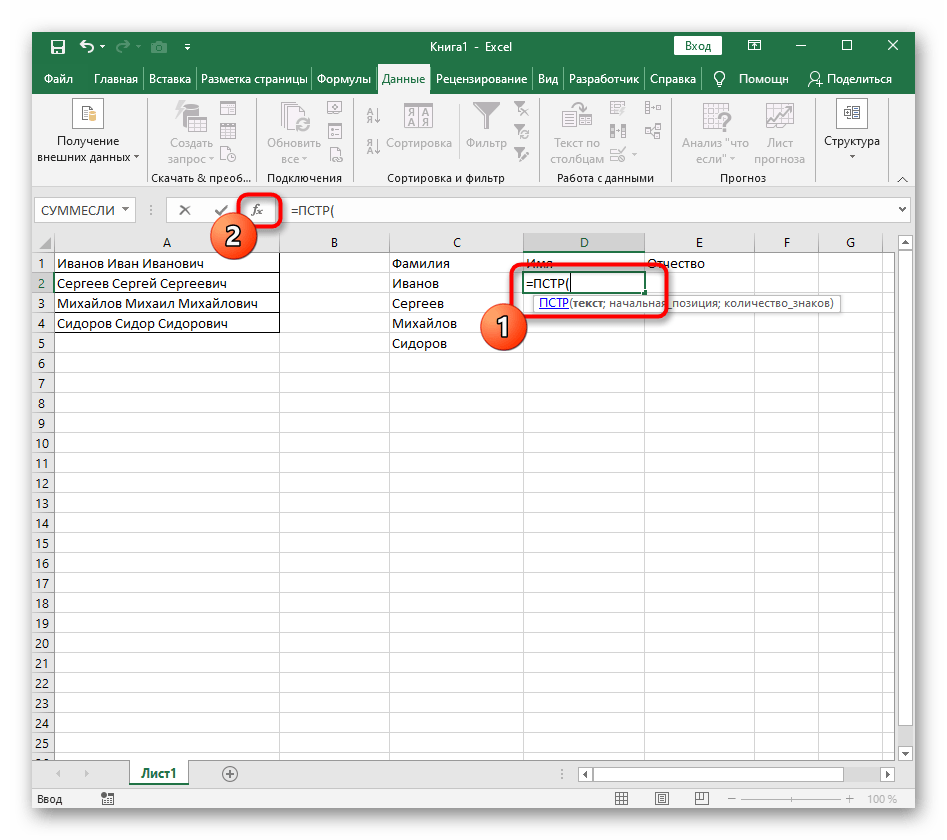
- Выберите ячейку, где хотите расположить первое слово, и запишите формулу
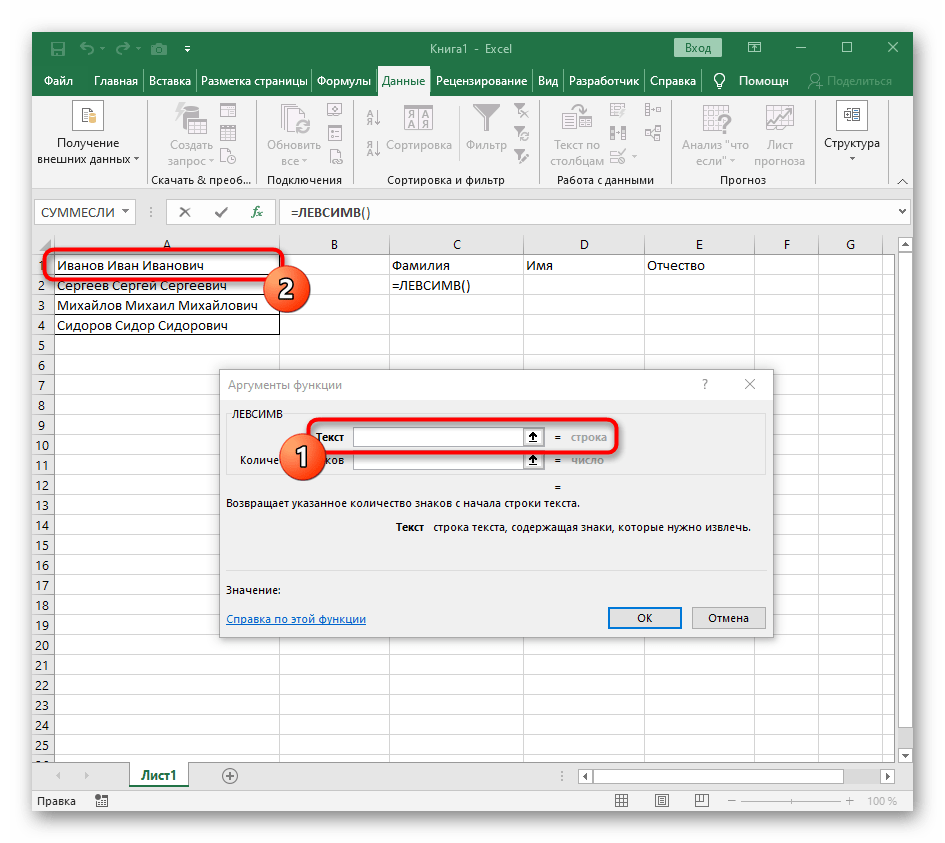
=ЛЕВСИМВ(. - После этого нажмите кнопку «Аргументы функции», перейдя тем самым в графическое окно редактирования формулы.
- В качестве текста аргумента указывайте ячейку с надписью, кликнув по ней левой кнопкой мыши на таблице.
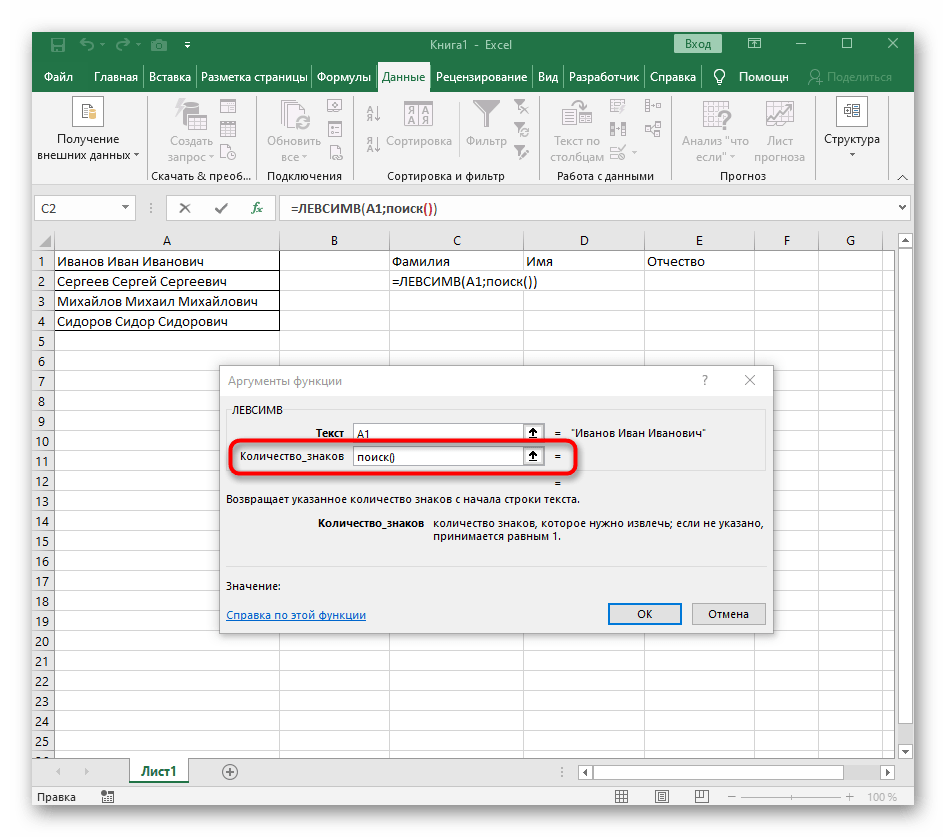
- Количество знаков до пробела или другого разделителя придется посчитать, но вручную мы это делать не будем, а воспользуемся еще одной формулой —
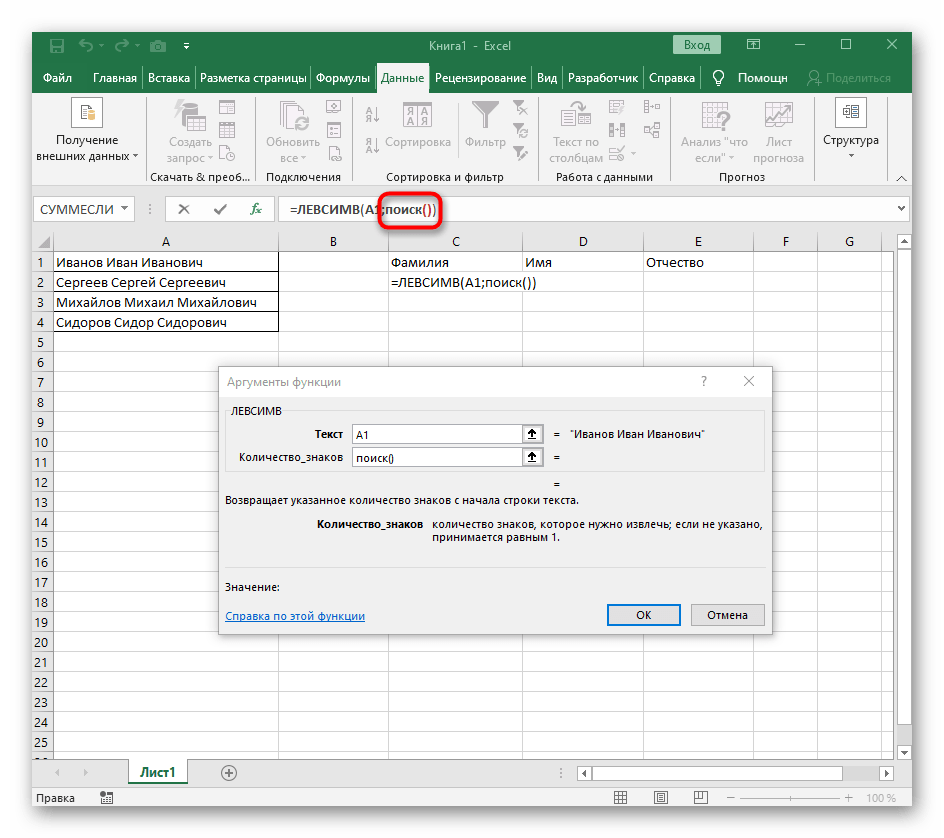
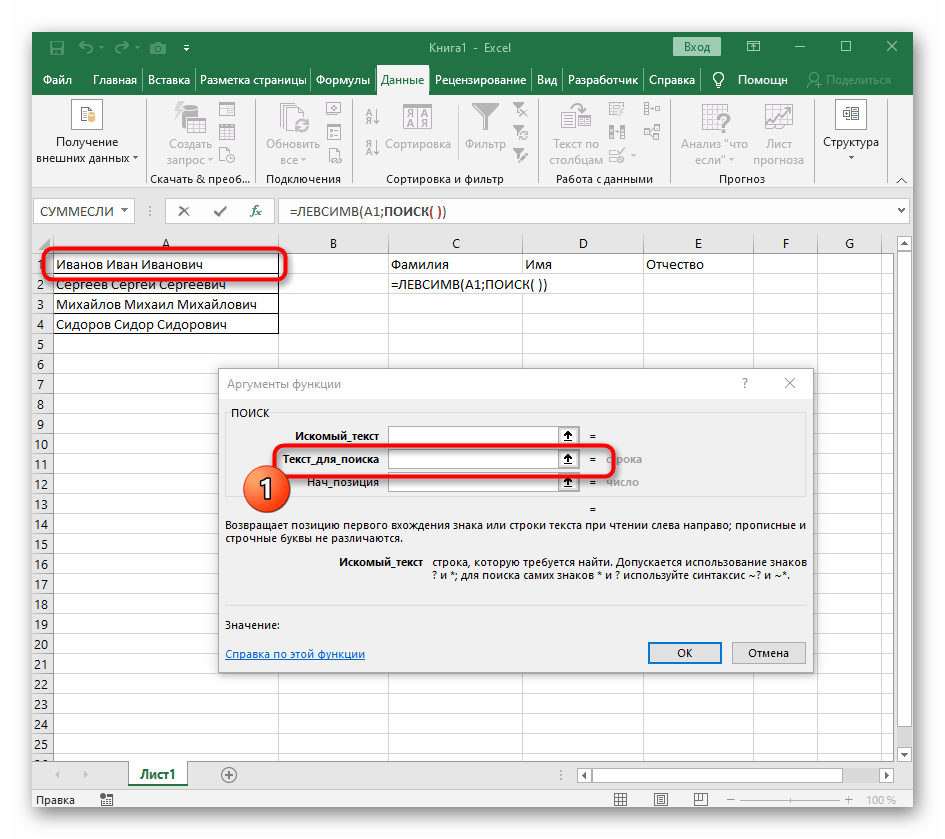
ПОИСК(). - Как только вы запишете ее в таком формате, она отобразится в тексте ячейки сверху и будет выделена жирным. Нажмите по ней для быстрого перехода к аргументам этой функции.
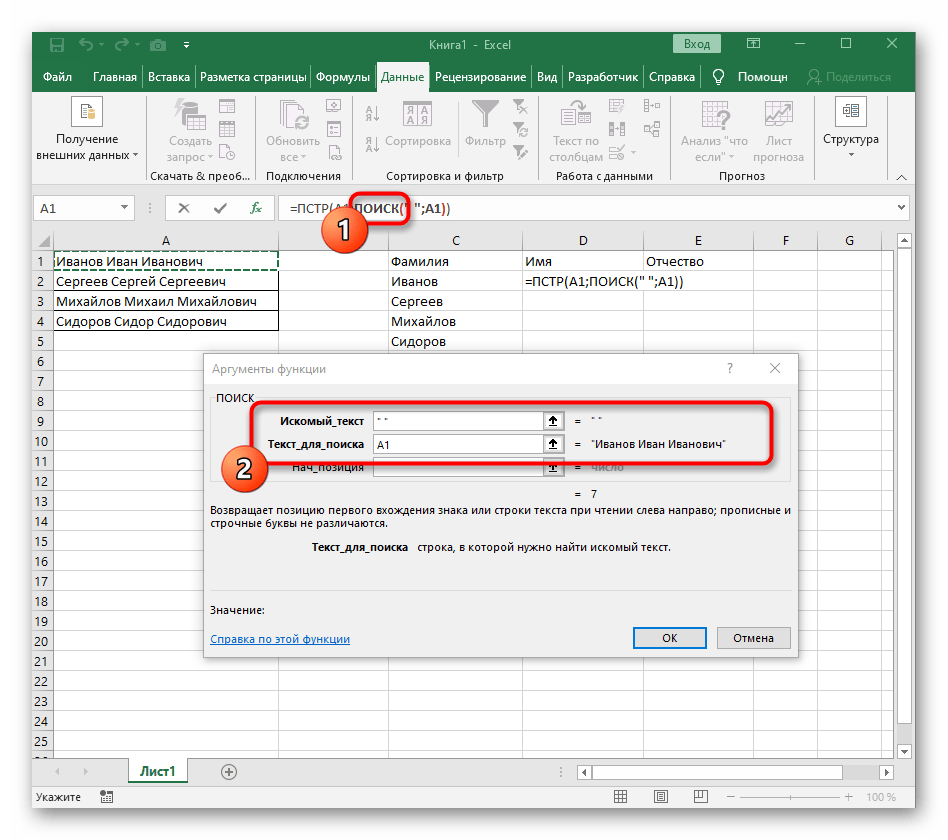
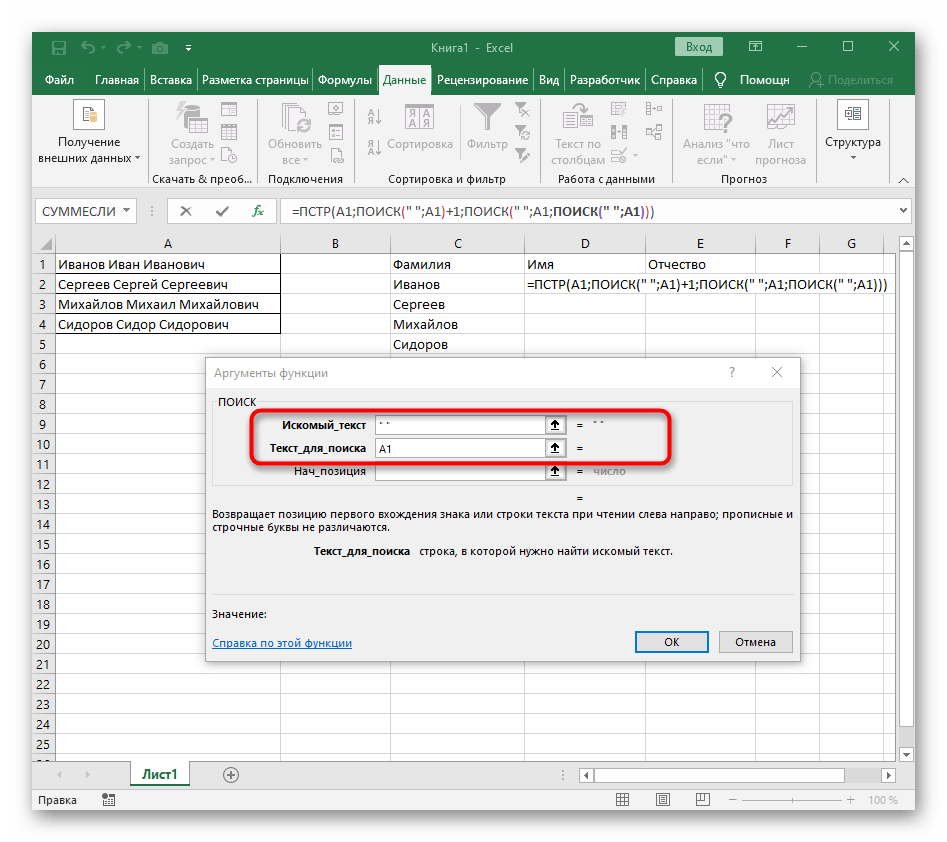
- В поле «Искомый_текст» просто поставьте пробел или используемый разделитель, поскольку он поможет понять, где заканчивается слово. В «Текст_для_поиска» укажите ту же обрабатываемую ячейку.
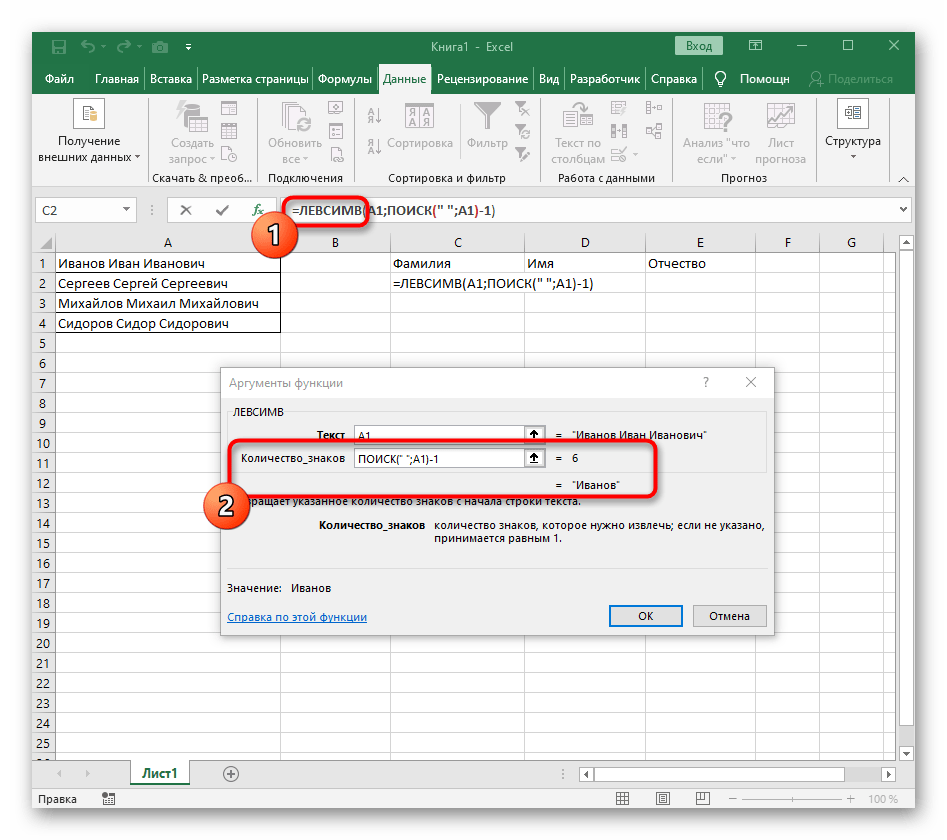
- Нажмите по первой функции, чтобы вернуться к ней, и добавьте в конце второго аргумента
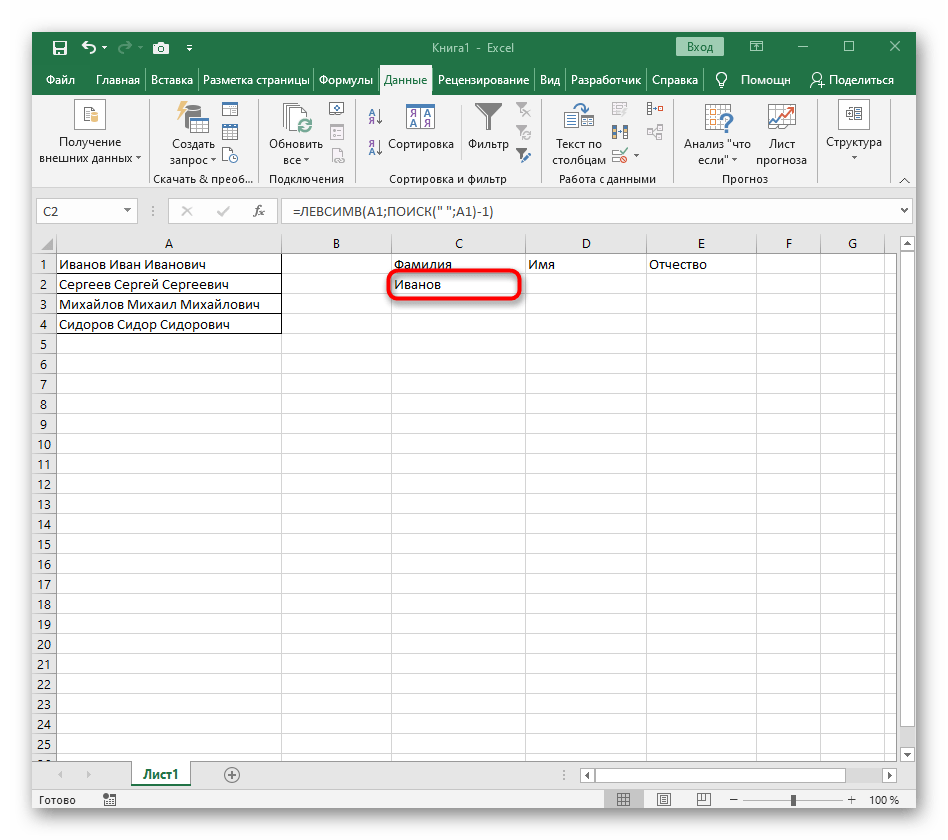
-1. Это необходимо для того, чтобы формуле «ПОИСК» учитывать не искомый пробел, а символ до него. Как видно на следующем скриншоте, в результате выводится фамилия без каких-либо пробелов, а это значит, что составление формул выполнено правильно. - Закройте редактор функции и убедитесь в том, что слово корректно отображается в новой ячейке.
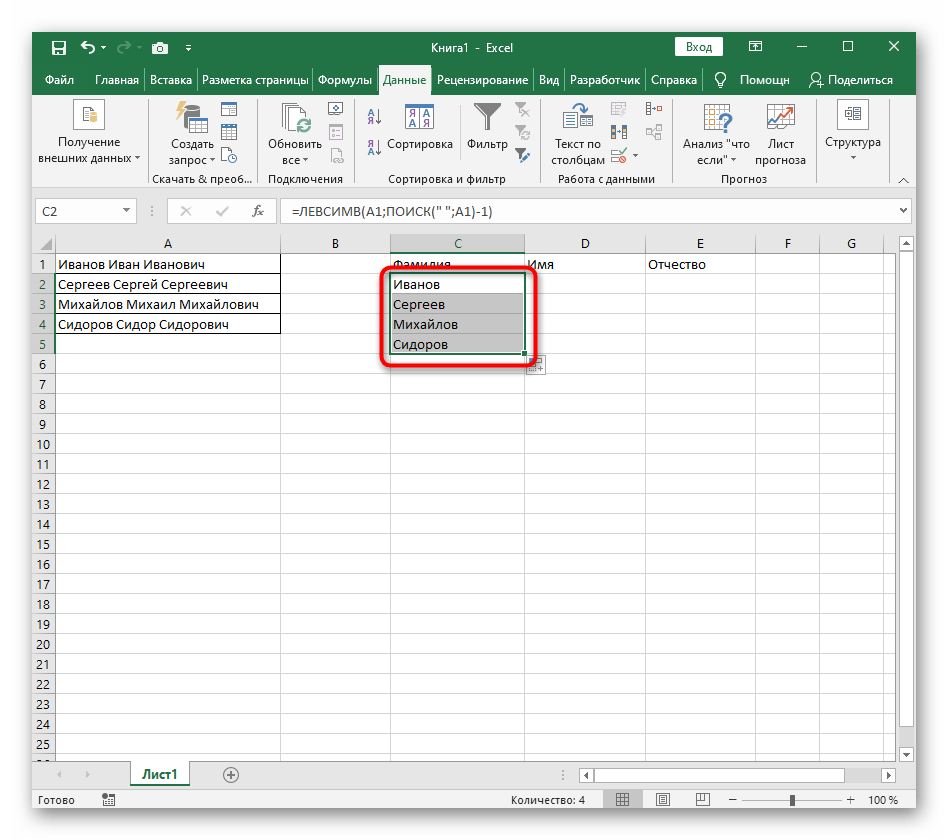
- Зажмите ячейку в правом нижнем углу и перетащите вниз на необходимое количество рядов, чтобы растянуть ее. Так подставляются значения других выражений, которые необходимо разделить, а выполнение формулы происходит автоматически.
Полностью созданная формула имеет вид =ЛЕВСИМВ(A1;ПОИСК(" ";A1)-1), вы же можете создать ее по приведенной выше инструкции или вставить эту, если условия и разделитель подходят. Не забывайте заменить обрабатываемую ячейку.
Шаг 2: Разделение второго слова
Самое трудное — разделить второе слово, которым в нашем случае является имя. Связано это с тем, что оно с двух сторон окружено пробелами, поэтому придется учитывать их оба, создавая массивную формулу для правильного расчета позиции.
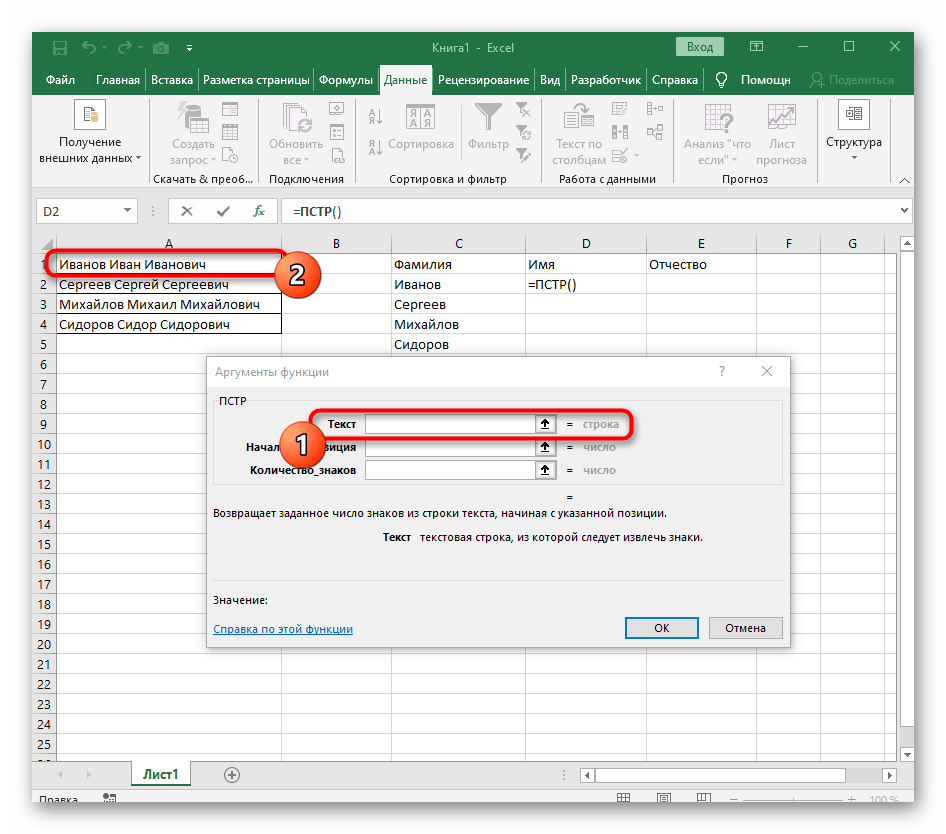
- В этом случае основной формулой станет
=ПСТР(— запишите ее в таком виде, а затем переходите к окну настройки аргументов. - Данная формула будет искать нужную строку в тексте, в качестве которого и выбираем ячейку с надписью для разделения.
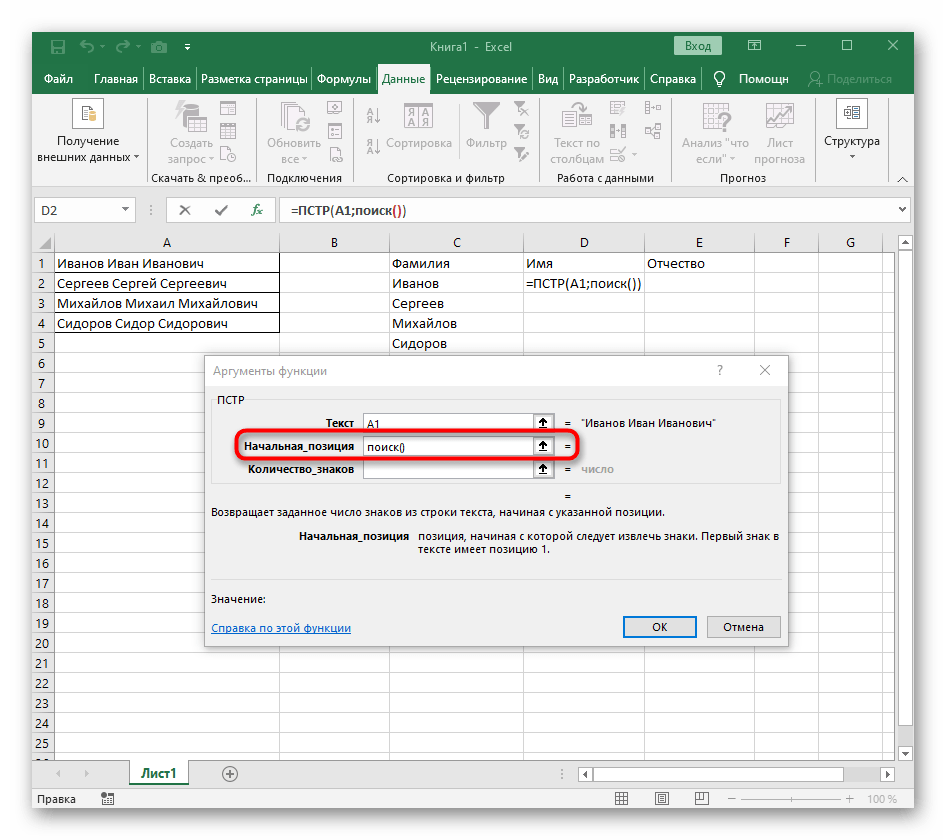
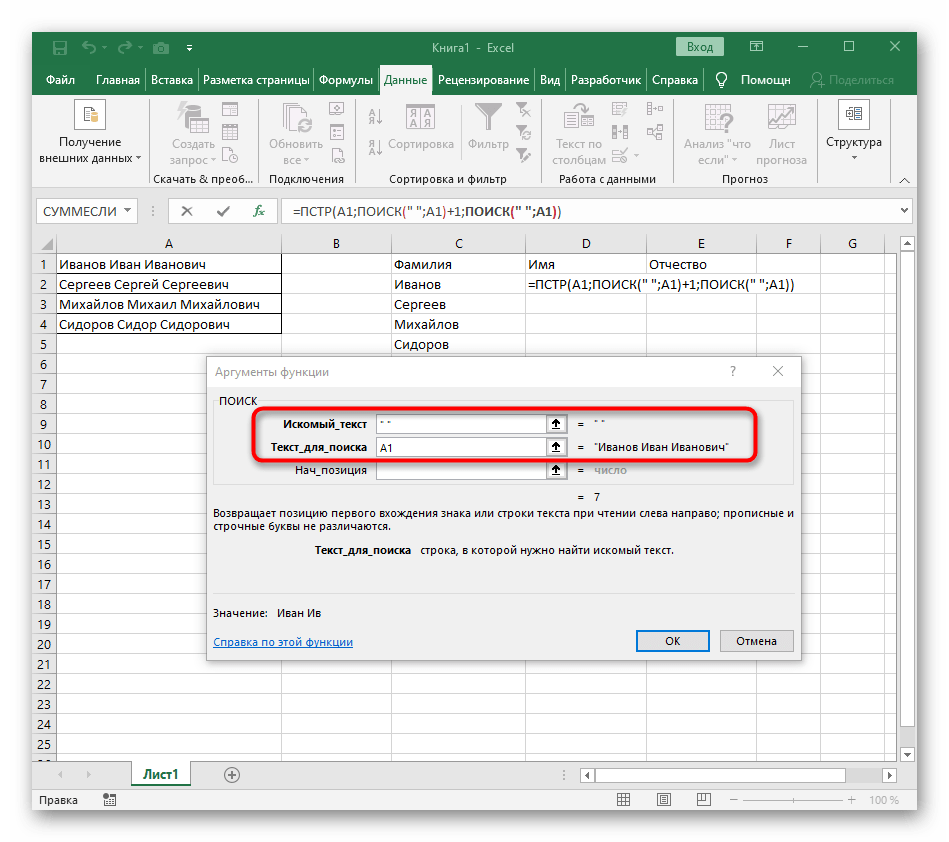
- Начальную позицию строки придется определять при помощи уже знакомой вспомогательной формулы
ПОИСК(). - Создав и перейдя к ней, заполните точно так же, как это было показано в предыдущем шаге. В качестве искомого текста используйте разделитель, а ячейку указывайте как текст для поиска.
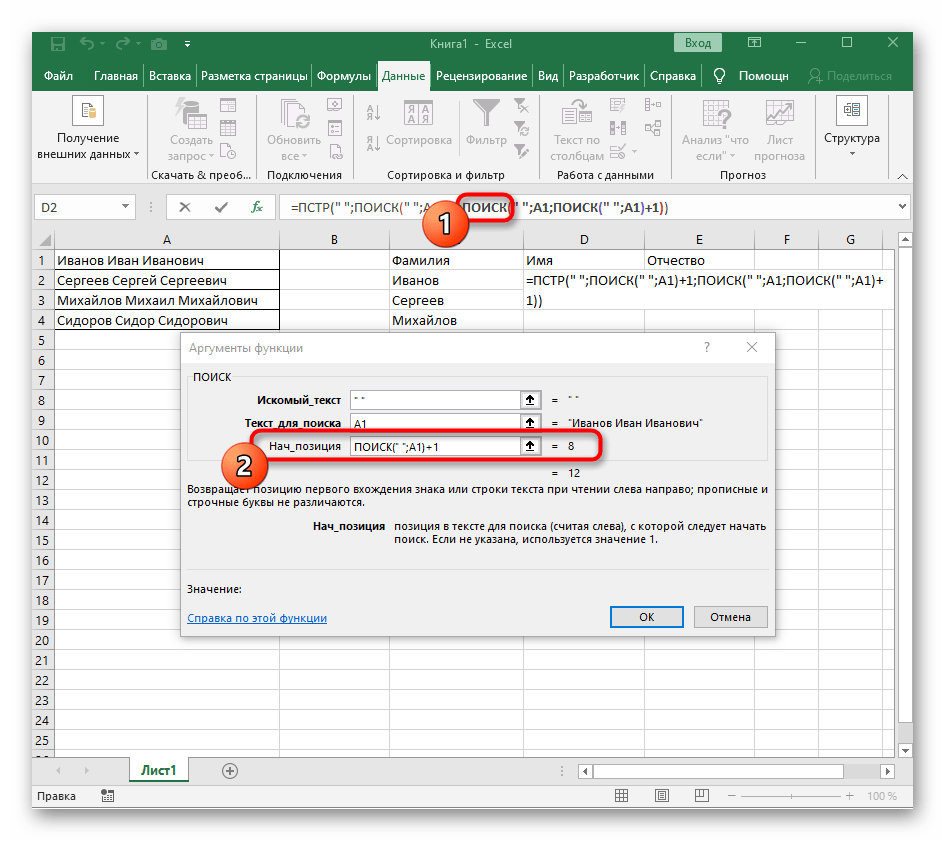
- Вернитесь к предыдущей формуле, где добавьте к функции «ПОИСК»
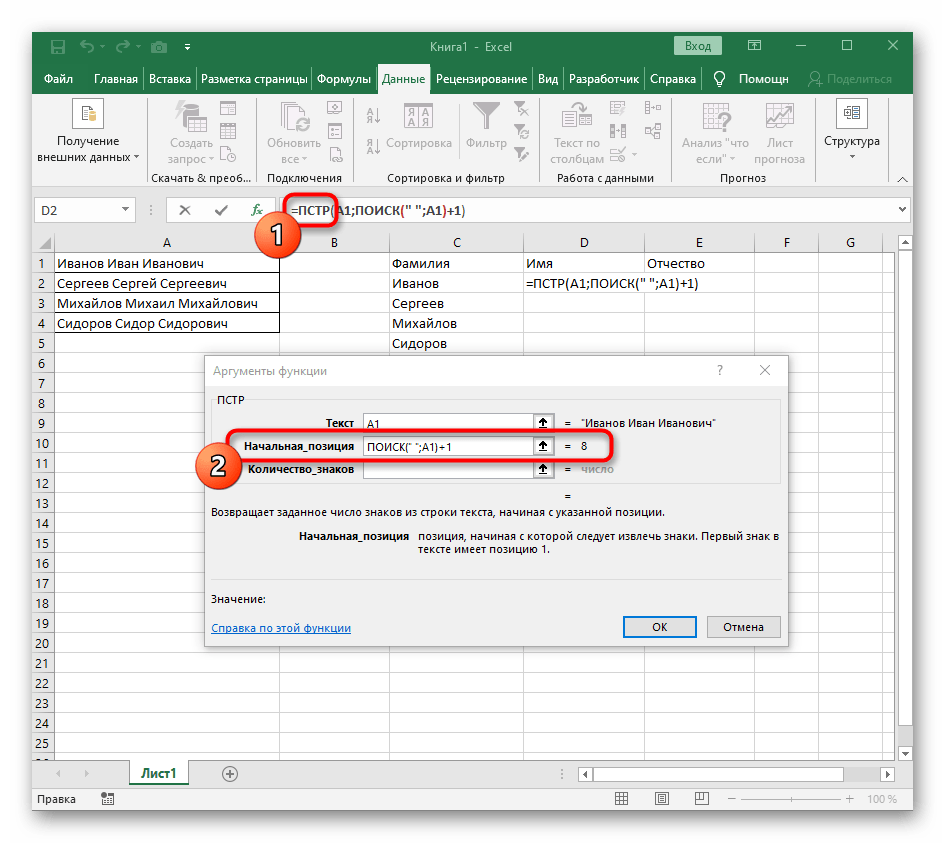
+1в конце, чтобы начинать счет со следующего символа после найденного пробела. - Сейчас формула уже может начать поиск строки с первого символа имени, но она пока еще не знает, где его закончить, поэтому в поле «Количество_знаков» снова впишите формулу
ПОИСК(). - Перейдите к ее аргументам и заполните их в уже привычном виде.
- Ранее мы не рассматривали начальную позицию этой функции, но теперь там нужно вписать тоже
ПОИСК(), поскольку эта формула должна находить не первый пробел, а второй. - Перейдите к созданной функции и заполните ее таким же образом.
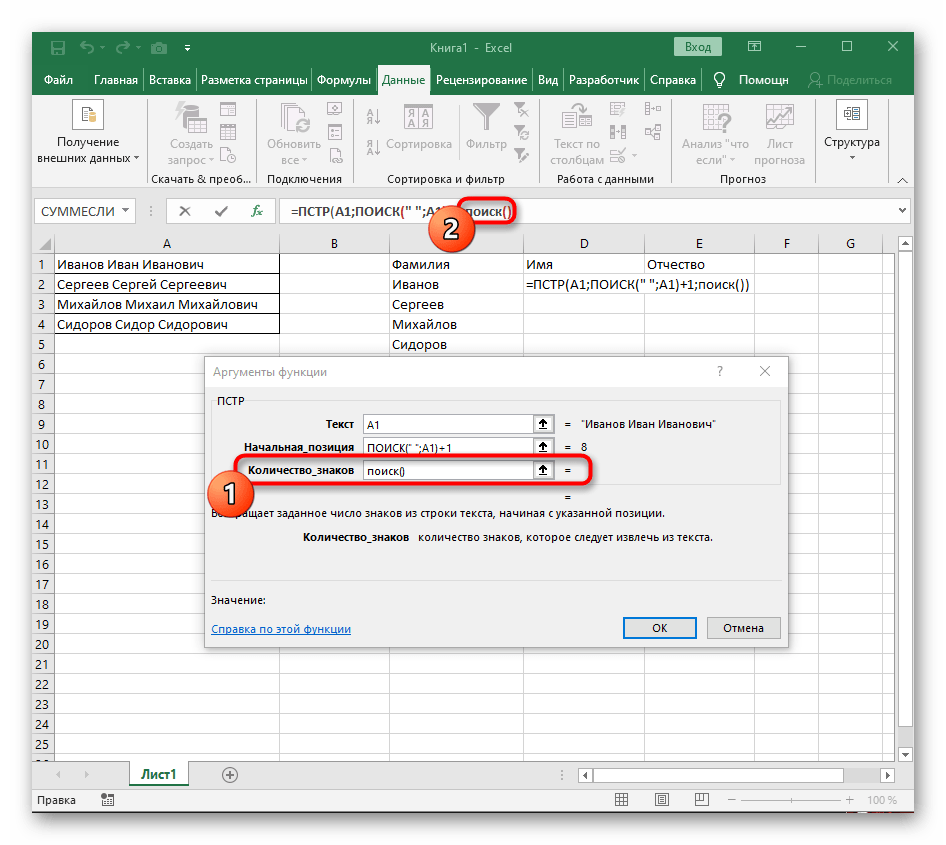
- Возвращайтесь к первому
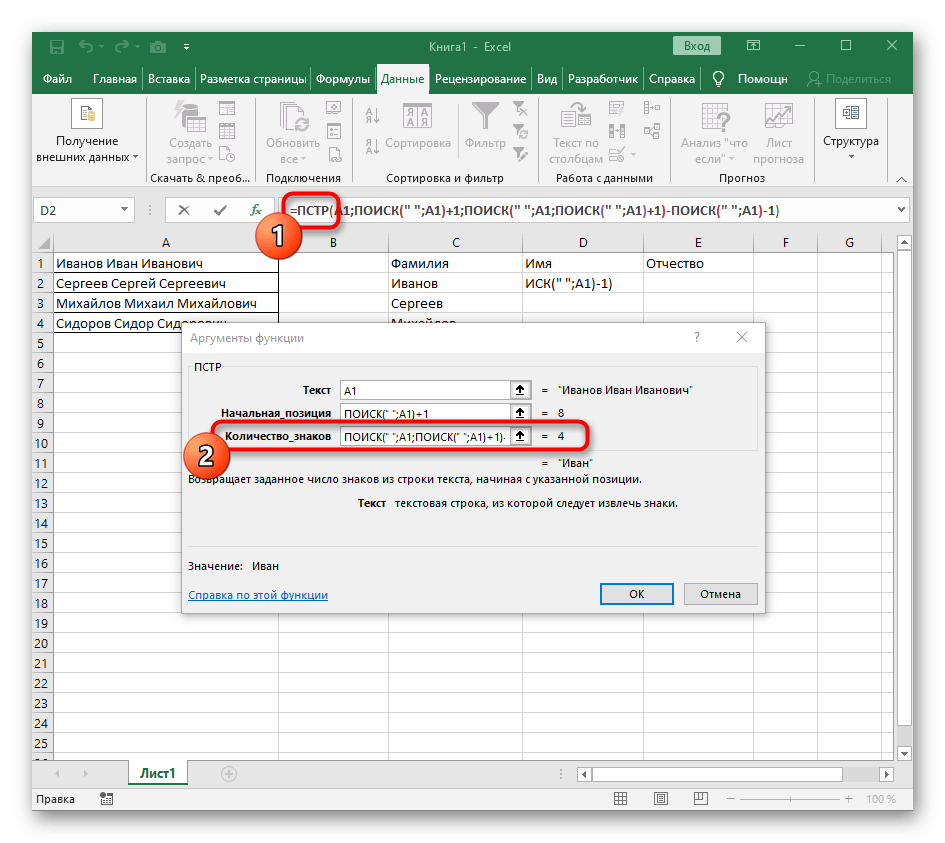
"ПОИСКУ"и допишите в «Нач_позиция»+1в конце, ведь для поиска строки нужен не пробел, а следующий символ. - Кликните по корню
=ПСТРи поставьте курсор в конце строки «Количество_знаков». - Допишите там выражение
-ПОИСК(" ";A1)-1)для завершения расчетов пробелов. - Вернитесь к таблице, растяните формулу и удостоверьтесь в том, что слова отображаются правильно.
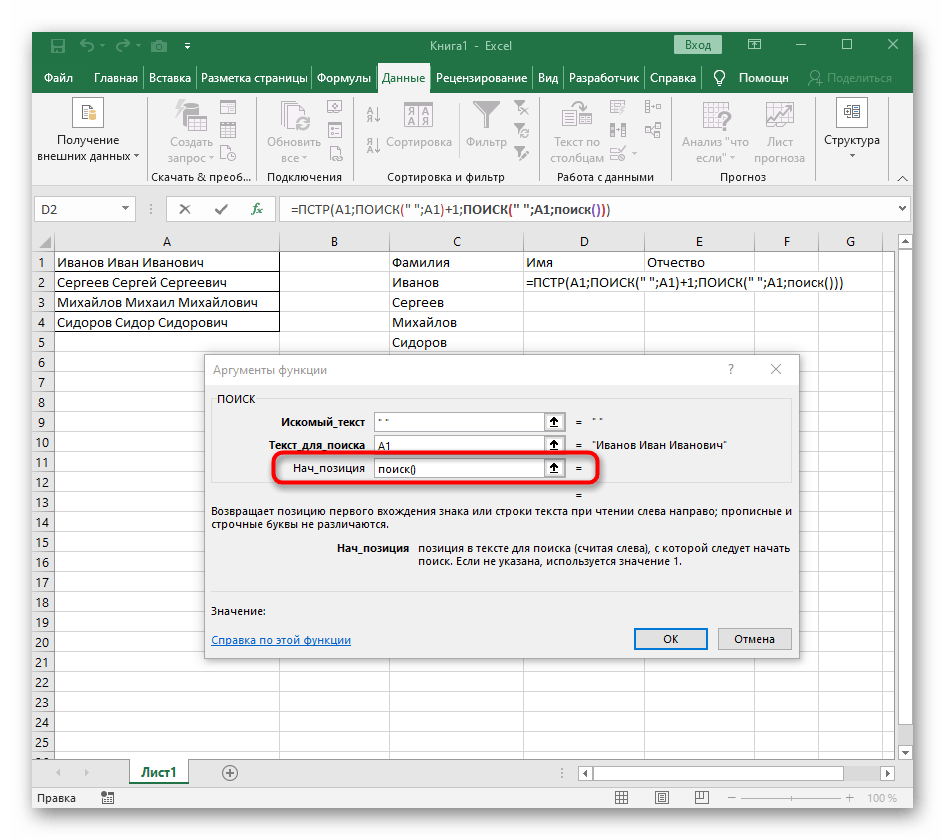
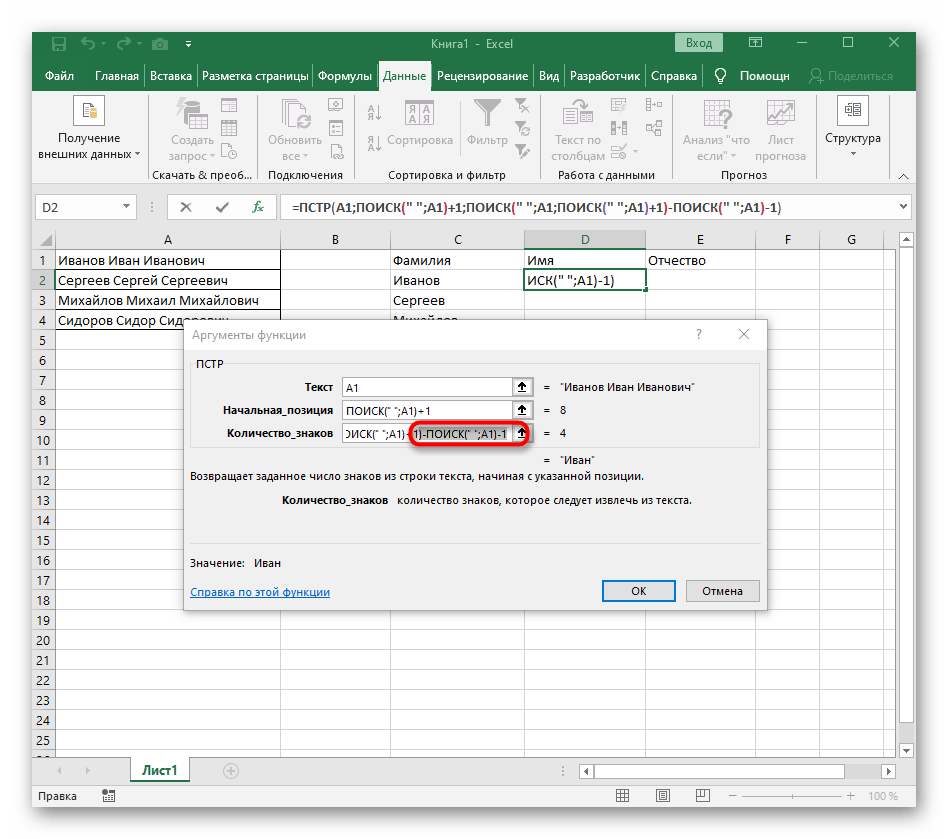
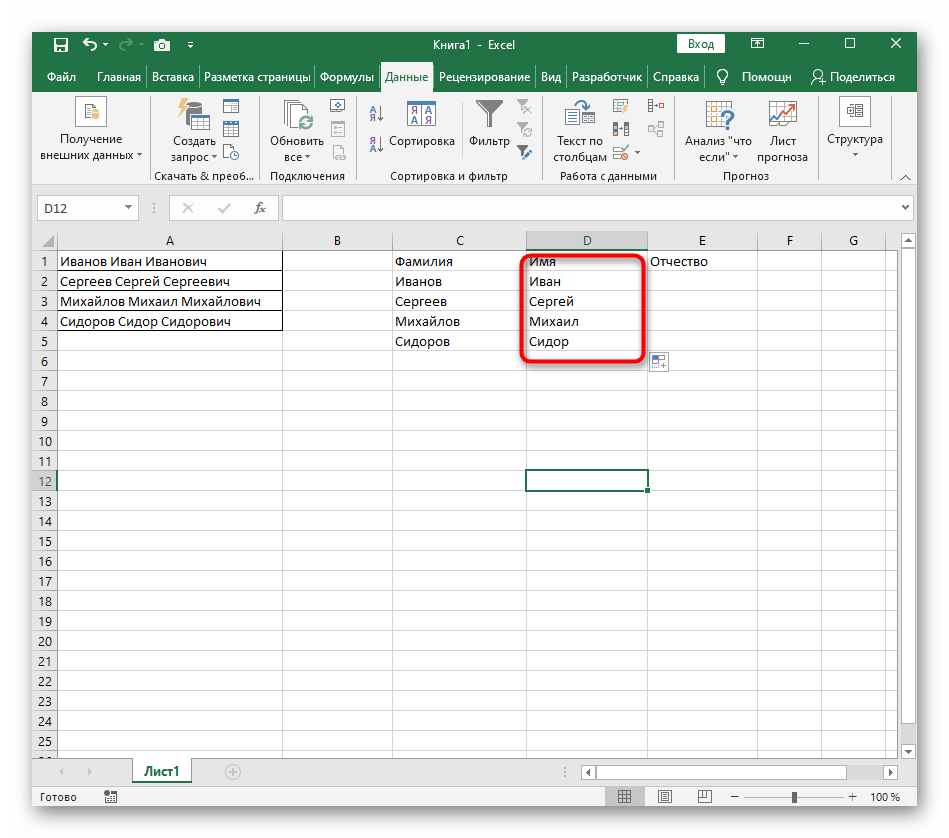
Формула получилась большая, и не все пользователи понимают, как именно она работает. Дело в том, что для поиска строки пришлось использовать сразу несколько функций, определяющих начальные и конечные позиции пробелов, а затем от них отнимался один символ, чтобы в результате эти самые пробелы не отображались. В итоге формула такая: =ПСТР(A1;ПОИСК(" ";A1)+1;ПОИСК(" ";A1;ПОИСК(" ";A1)+1)-ПОИСК(" ";A1)-1). Используйте ее в качестве примера, заменяя номер ячейки с текстом.
Шаг 3: Разделение третьего слова
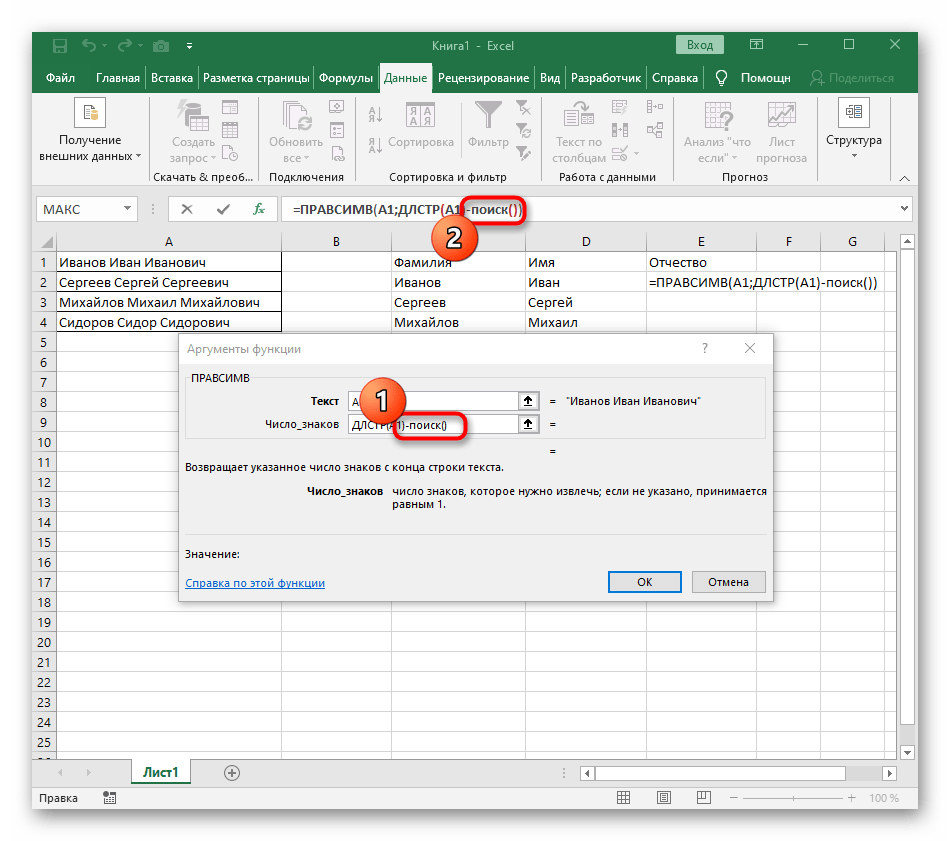
Последний шаг нашей инструкции подразумевает разделение третьего слова, что выглядит примерно так же, как это происходило с первым, но общая формула немного меняется.
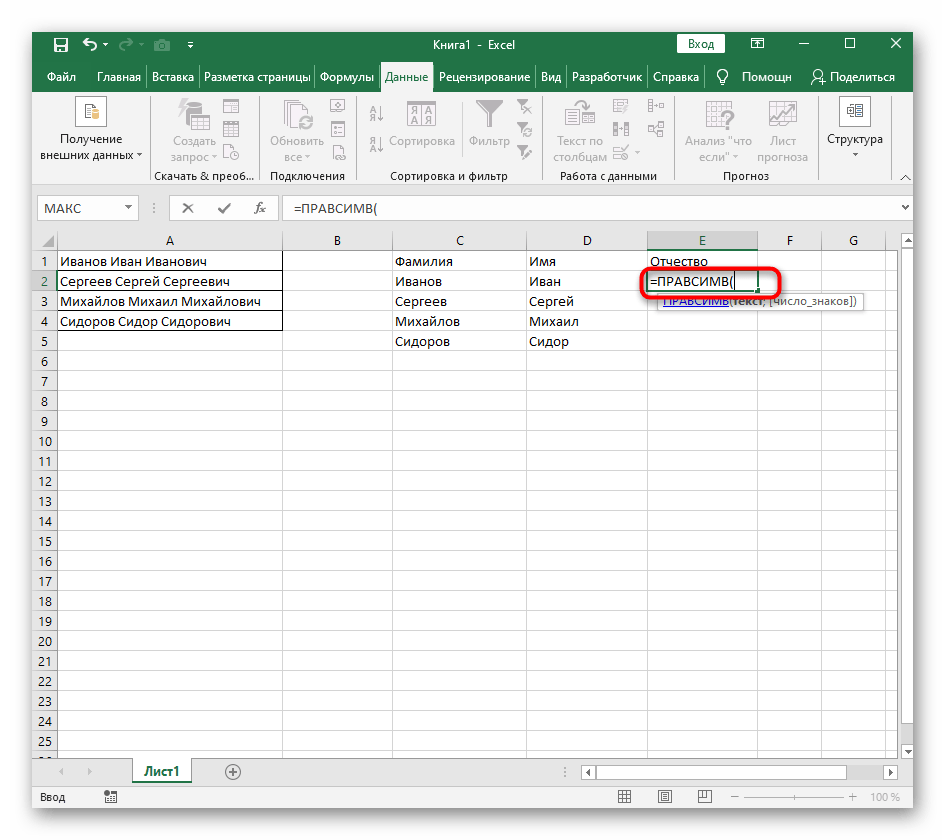
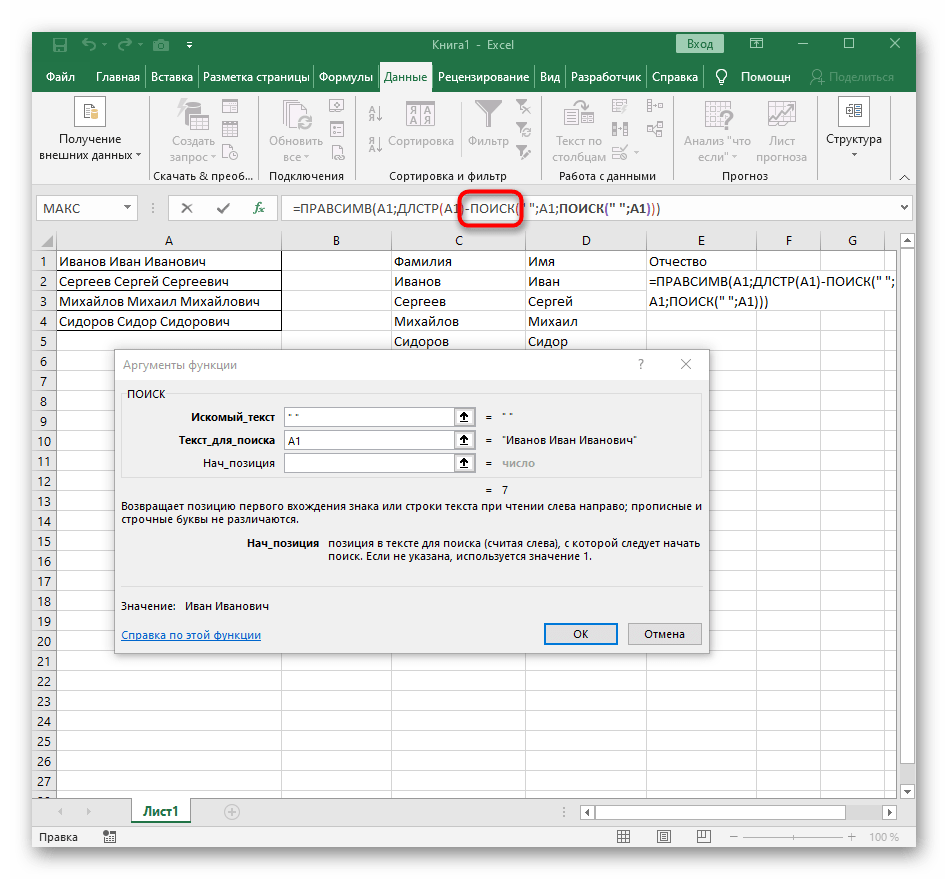
- В пустой ячейке для расположения будущего текста напишите
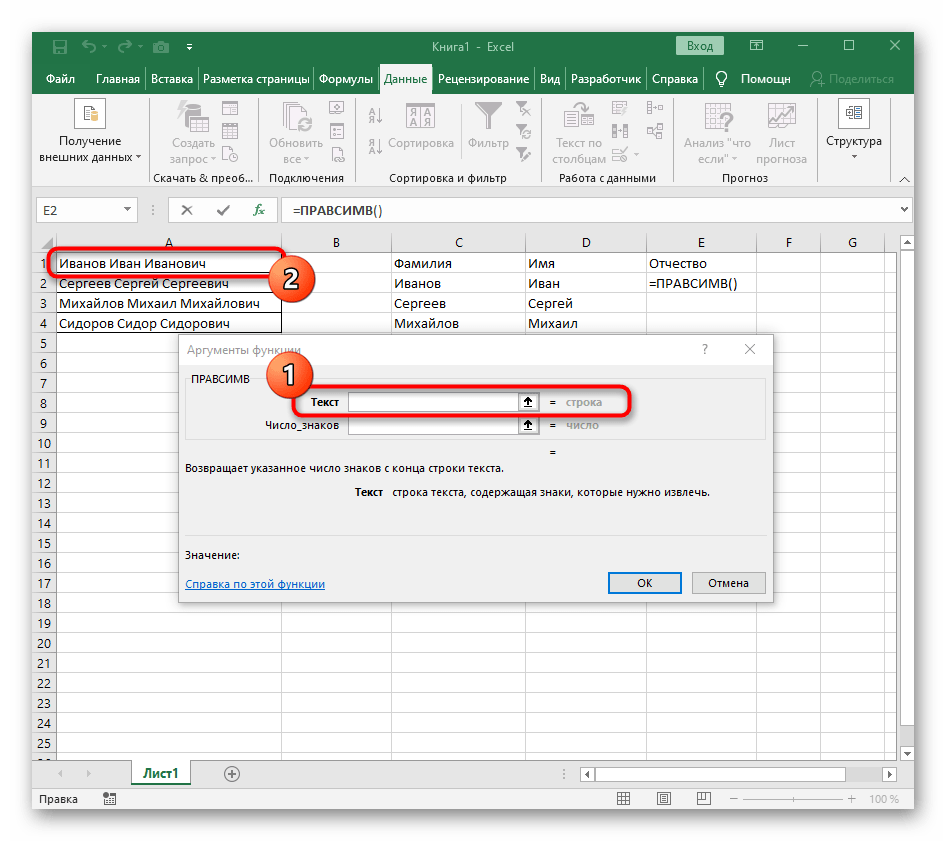
=ПРАВСИМВ(и перейдите к аргументам этой функции. - В качестве текста указывайте ячейку с надписью для разделения.
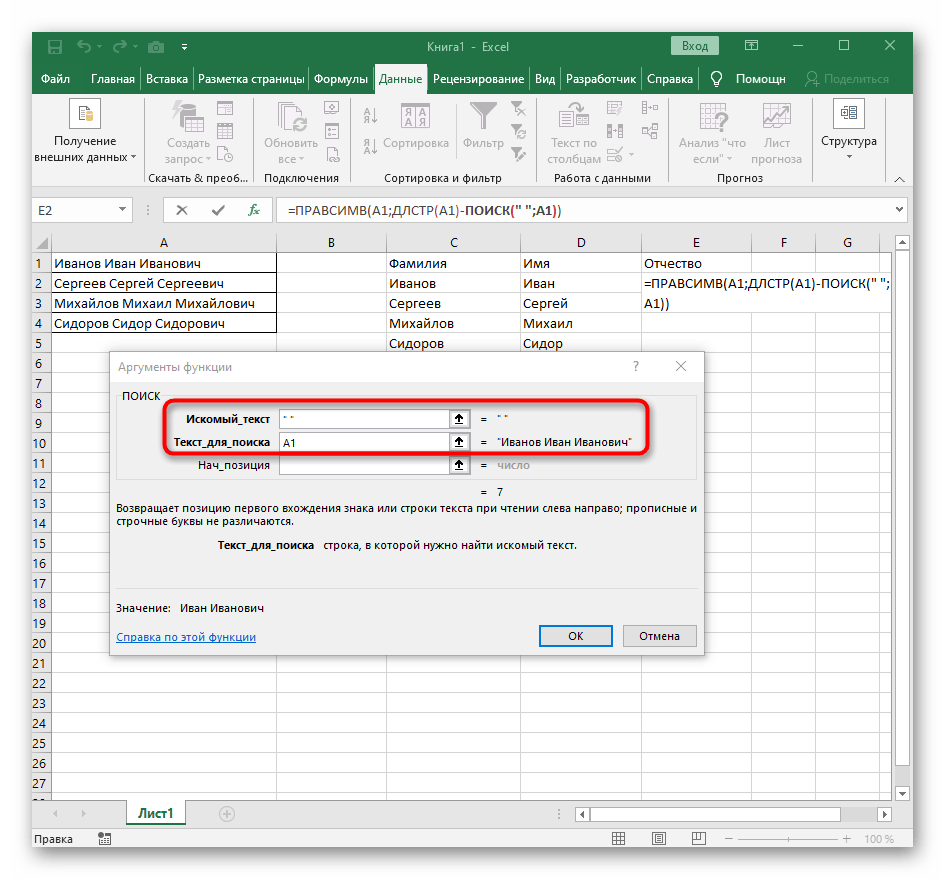
- В этот раз вспомогательная функция для поиска слова называется
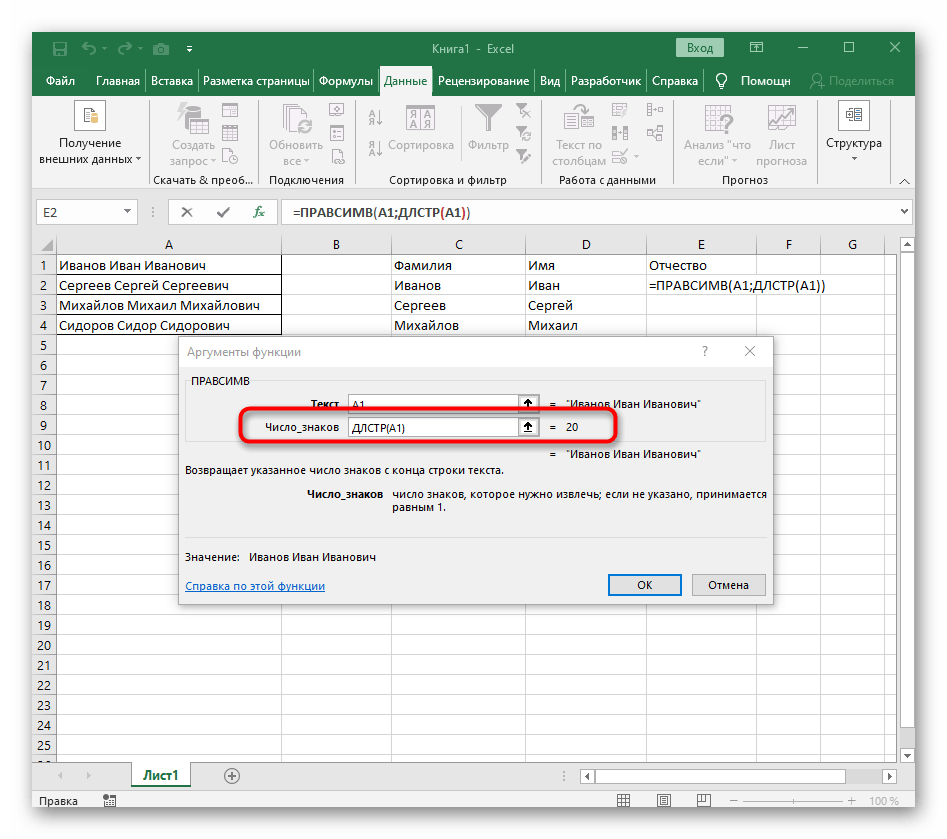
ДЛСТР(A1), где A1 — та же самая ячейка с текстом. Эта функция определяет количество знаков в тексте, а нам останется выделить только подходящие. - Для этого добавьте
-ПОИСК()и перейдите к редактированию этой формулы. - Введите уже привычную структуру для поиска первого разделителя в строке.
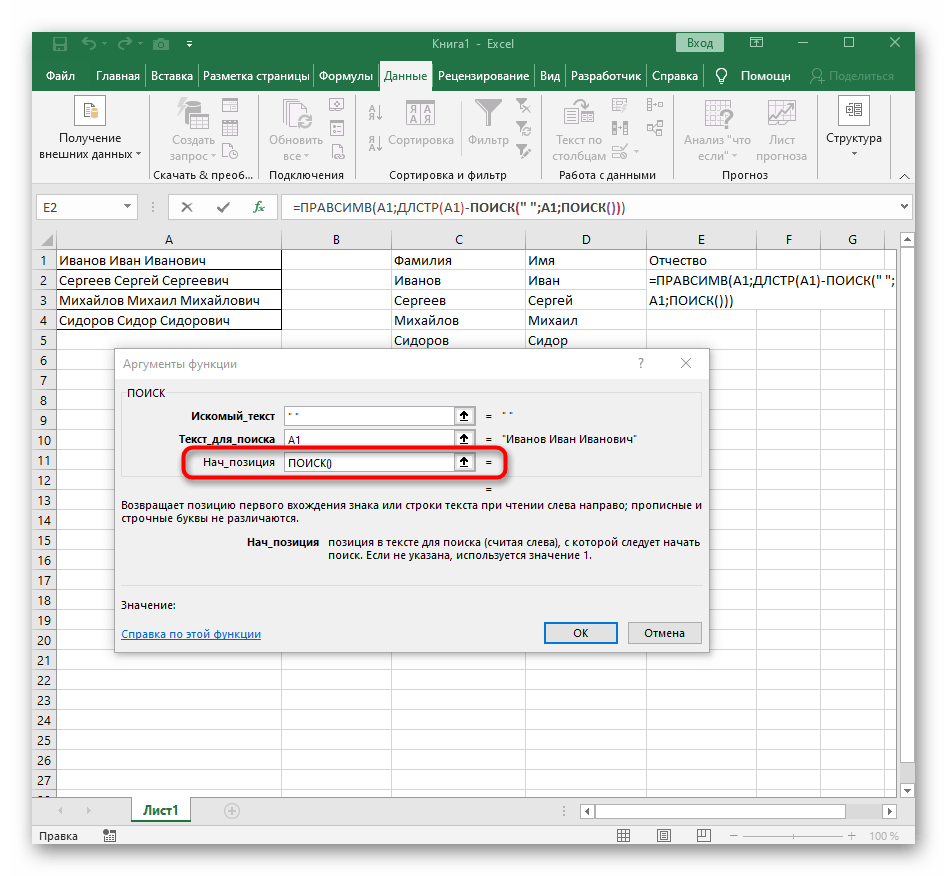
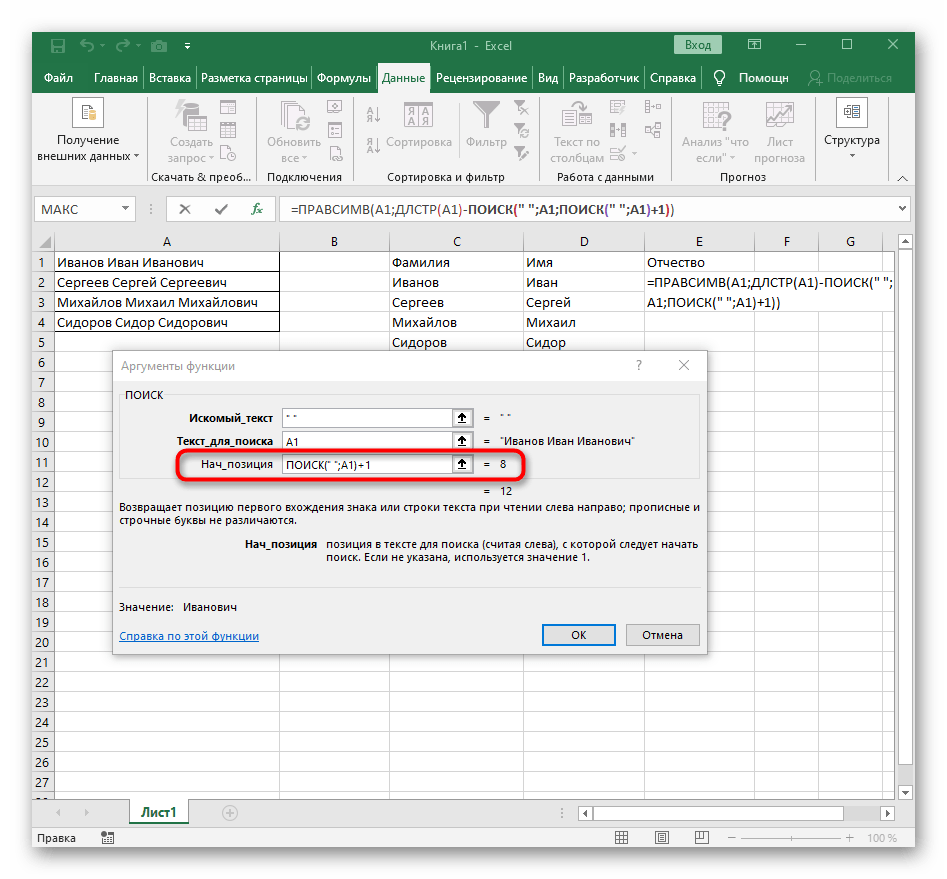
- Добавьте для начальной позиции еще один
ПОИСК(). - Ему укажите ту же самую структуру.
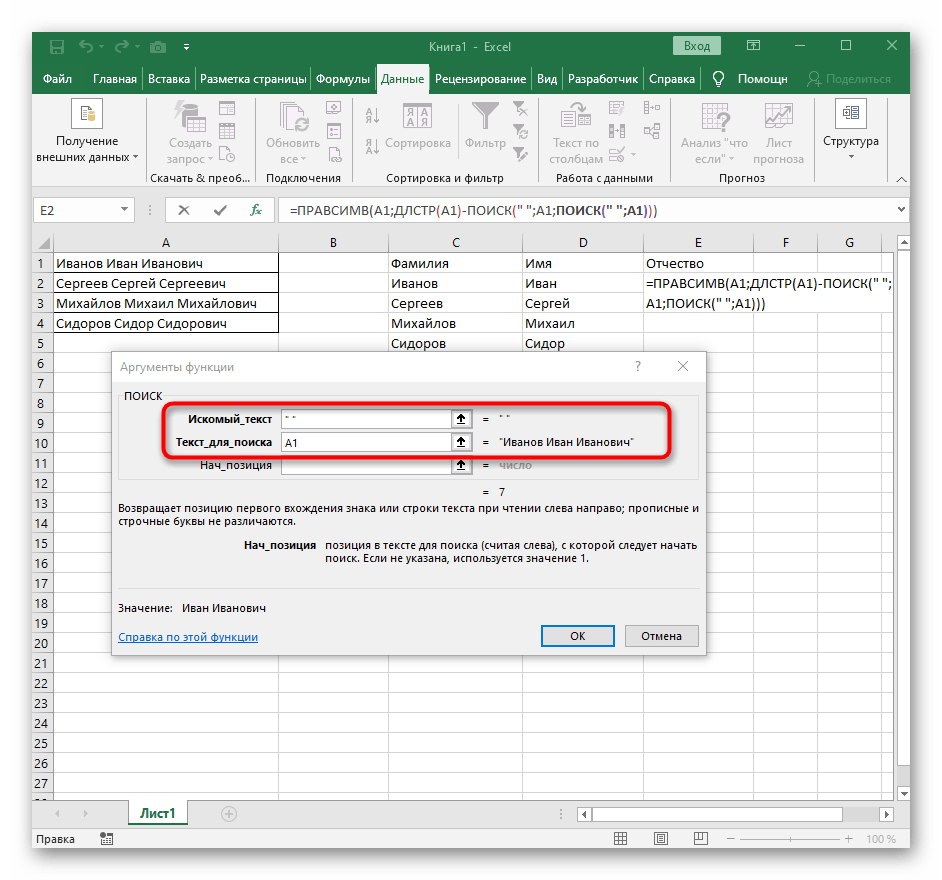
- Вернитесь к предыдущей формуле «ПОИСК».
- Прибавьте для его начальной позиции
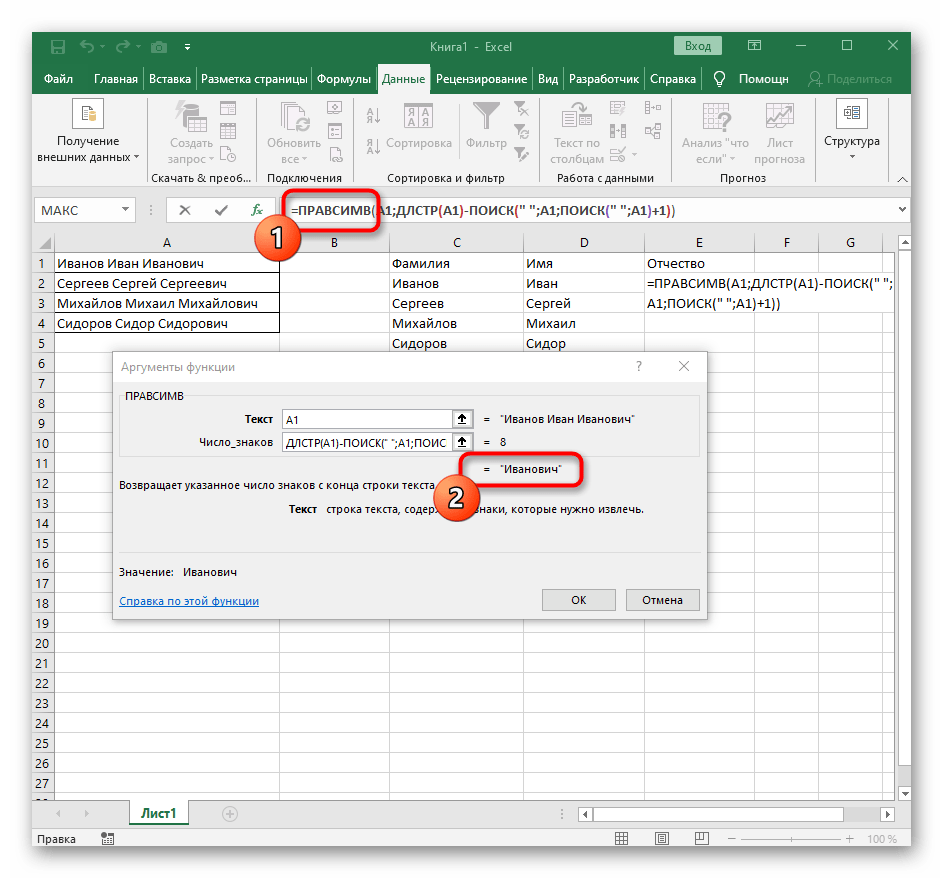
+1. - Перейдите к корню формулы
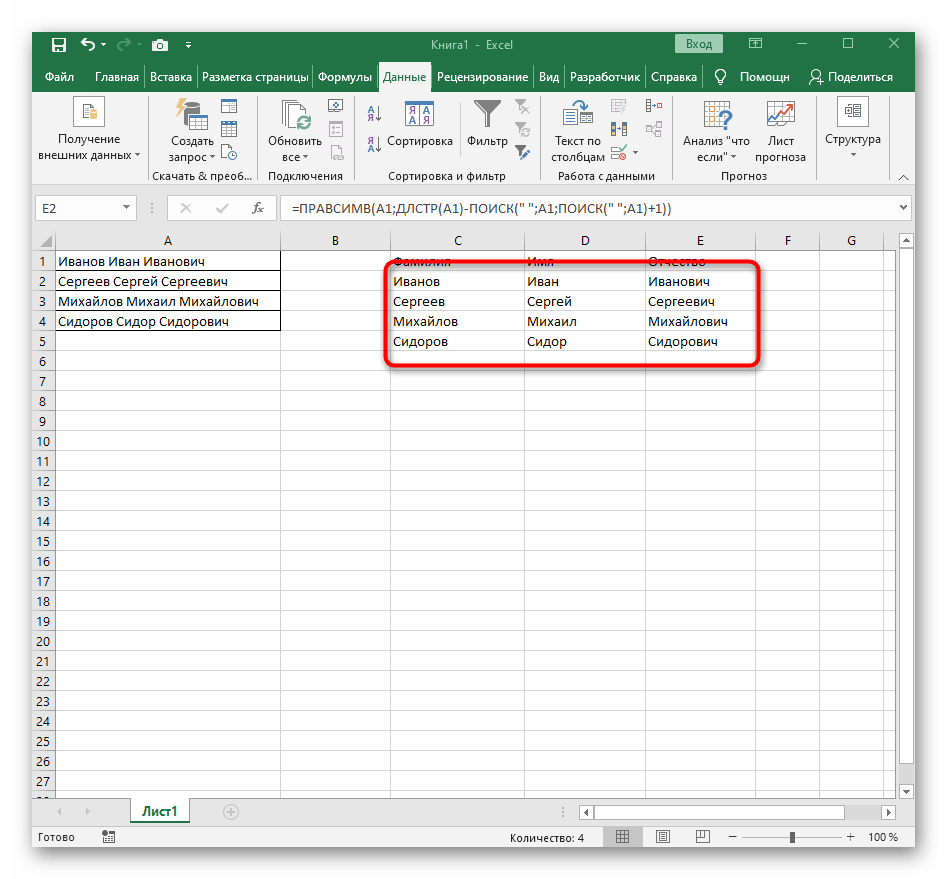
ПРАВСИМВи убедитесь в том, что результат отображается правильно, а уже потом подтверждайте внесение изменений. Полная формула в этом случае выглядит как=ПРАВСИМВ(A1;ДЛСТР(A1)-ПОИСК(" ";A1;ПОИСК(" ";A1)+1)). - В итоге на следующем скриншоте вы видите, что все три слова разделены правильно и находятся в своих столбцах. Для этого пришлось использовать самые разные формулы и вспомогательные функции, но это позволяет динамически расширять таблицу и не беспокоиться о том, что каждый раз придется разделять текст заново. По необходимости просто расширяйте формулу путем ее перемещения вниз, чтобы следующие ячейки затрагивались автоматически.
 Наш Telegram каналТолько полезная информация
Наш Telegram каналТолько полезная информация
Похожие инструкции:
 Разделение столбцов в Microsoft Excel
Разделение столбцов в Microsoft Excel
 Разделение ячеек в таблице Microsoft Word
Разделение ячеек в таблице Microsoft Word
 Разделение PDF на страницы онлайн
Разделение PDF на страницы онлайн
 Разделение диска при установке Windows 10
Разделение диска при установке Windows 10
 Вертикальная запись текста в Microsoft Excel
Вертикальная запись текста в Microsoft Excel
 Вставка текста в ячейку с формулой в Microsoft Excel
Вставка текста в ячейку с формулой в Microsoft Excel
 Переворот текста на 180 градусов в Microsoft Excel
Переворот текста на 180 градусов в Microsoft Excel
 Объединение строк в Microsoft Excel
Объединение строк в Microsoft Excel
 Расчет суммы произведений в Excel
Расчет суммы произведений в Excel
 Разъединение ячеек в Microsoft Excel
Разъединение ячеек в Microsoft Excel
 Удаление формулы в Microsoft Excel
Удаление формулы в Microsoft Excel
 Замена запятой на точку в Microsoft Excel
Замена запятой на точку в Microsoft Excel
 Удаление лишних пробелов в Microsoft Excel
Удаление лишних пробелов в Microsoft Excel
 Выделение ячеек в Microsoft Excel
Выделение ячеек в Microsoft Excel
 4 способа переименования листа в Microsoft Excel
4 способа переименования листа в Microsoft Excel
 Вычитание в программе Microsoft Excel
Вычитание в программе Microsoft Excel
 Создание базы данных в Microsoft Excel
Создание базы данных в Microsoft Excel
 Изменение формата ячеек в Excel
Изменение формата ячеек в Excel
 Защита ячеек от редактирования в Microsoft Excel
Защита ячеек от редактирования в Microsoft Excel
 Удаление колонтитулов в Microsoft Excel
Удаление колонтитулов в Microsoft Excel
 Логические функции в программе Microsoft Excel
Логические функции в программе Microsoft Excel
 Создание гистограммы в Microsoft Excel
Создание гистограммы в Microsoft Excel
 Установка пароля на файлы в программе Microsoft Excel
Установка пароля на файлы в программе Microsoft Excel
 Расчет среднего значения в программе Microsoft Excel
Расчет среднего значения в программе Microsoft Excel
 Функции программы Microsoft Excel: подбор параметра
Функции программы Microsoft Excel: подбор параметра
 Функция автофильтр в Microsoft Excel: особенности использования
Функция автофильтр в Microsoft Excel: особенности использования
 Умножение числа на процент в программе Microsoft Excel
Умножение числа на процент в программе Microsoft Excel
 Добавление новой строки в программе Microsoft Excel
Добавление новой строки в программе Microsoft Excel
Хорошая статья, спасибо!
Отличная статья, очень помогла
добрый день. имеется таблица, в ячейках — текст разной длины. ширина столбца фиксированная. как отформатировать ячейки так (по высоте), что бы было видно все содержимое, независимо от длины записи. Форматирование должно проходить в автоматическом режиме, т.е. в ячейку вставляются данные и высота ячейки регулируется сама?
спасибо огромное